低价网站建设扬州好听的平台名字大全
Azure通过自动化账户实现对资源变更
- 创建一个自动化账户
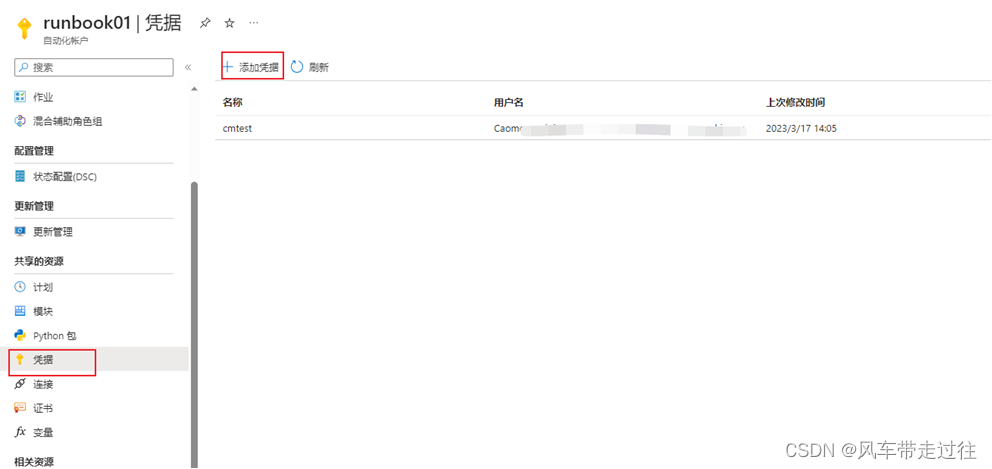
- 第一种方式 添加凭据(有更改资源权限的账户,没有auth认证情况)
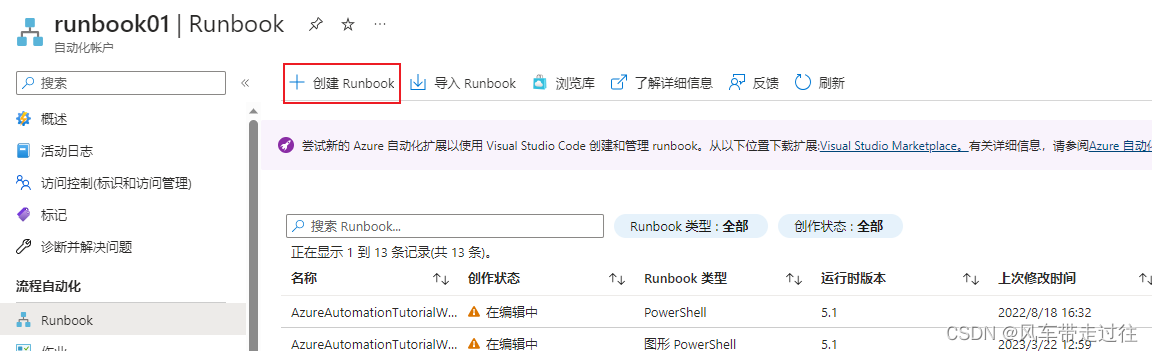
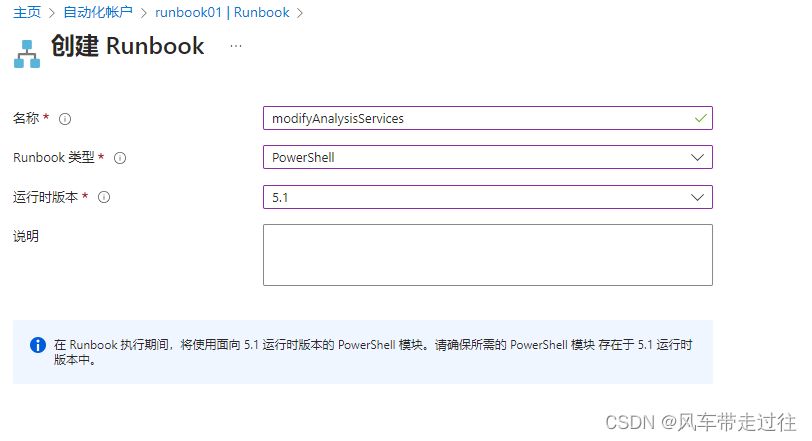
- 创建一个Runbook,测试修改 AnalysisServices 定价层
- 设置定时任务:
- 开始定时任务:
- 第二种方式,使用系统托管标识
- 在自动化账户的标识处状态调整为开
- 在Analysis Services中分配给标识所有者角色。
- 在自动化账户的标识处可以看到已分配的权限
- 测试
- 自助排错
创建一个自动化账户
参考文档:https://docs.azure.cn/zh-cn/automation/quickstarts/create-azure-automation-account-portal
第一种方式 添加凭据(有更改资源权限的账户,没有auth认证情况)
创建一个Runbook,测试修改 AnalysisServices 定价层
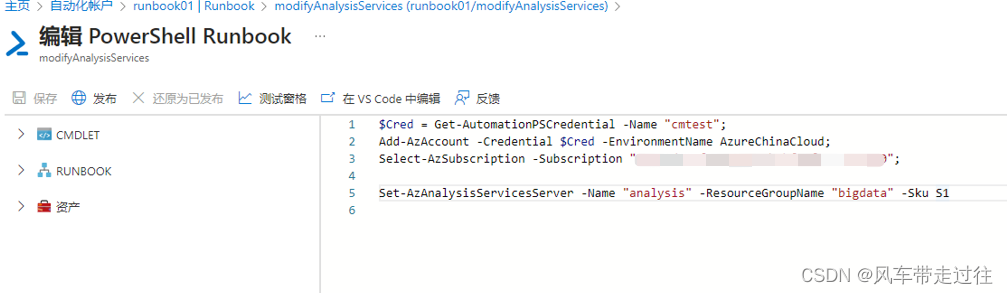
$Cred = Get-AutomationPSCredential -Name "cmtest";
Add-AzAccount -Credential $Cred -EnvironmentName AzureChinaCloud;
Select-AzSubscription -Subscription "361ced67-xxxx-xxxx-b2bf-7f215726e030";Set-AzAnalysisServicesServer -Name "analysis" -ResourceGroupName "bigdata" -Sku S1
#cmtest 为凭据名称
#361ced67-xxxx-xxxx-b2bf-7f215726e030 为订阅ID
#analysis 为资源AnalysisServices 名称
#bigdata 为资源组
#S1 为定价层
保存,并在测试窗格里面进行测试
若没有问题,点击发布。
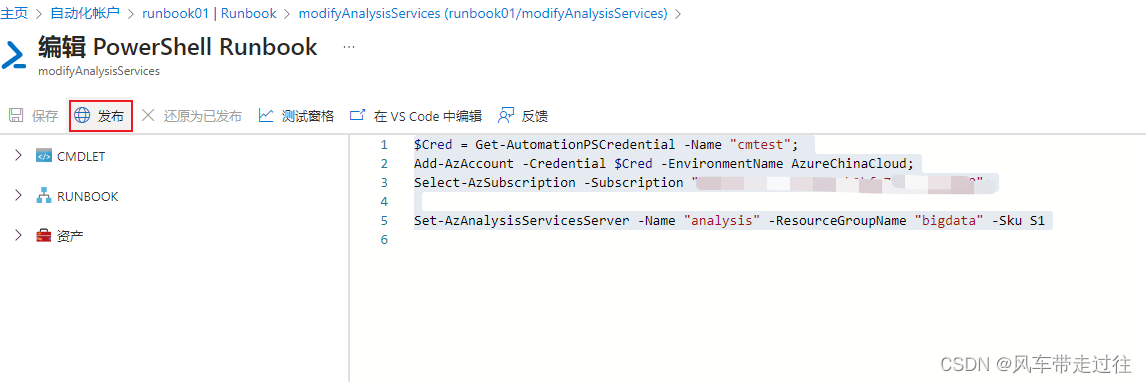
设置定时任务:
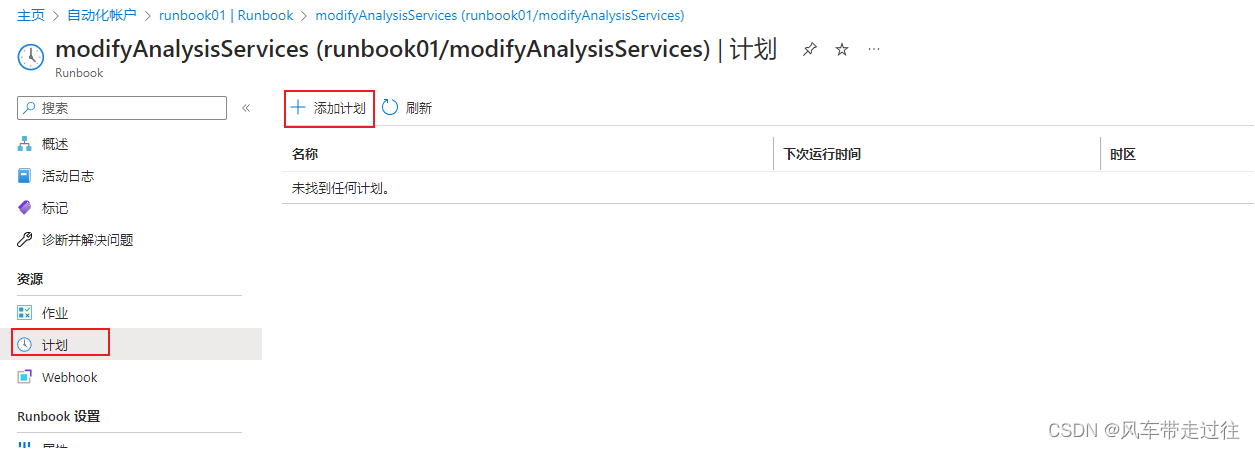
开始定时任务:
第二种方式,使用系统托管标识
在自动化账户的标识处状态调整为开
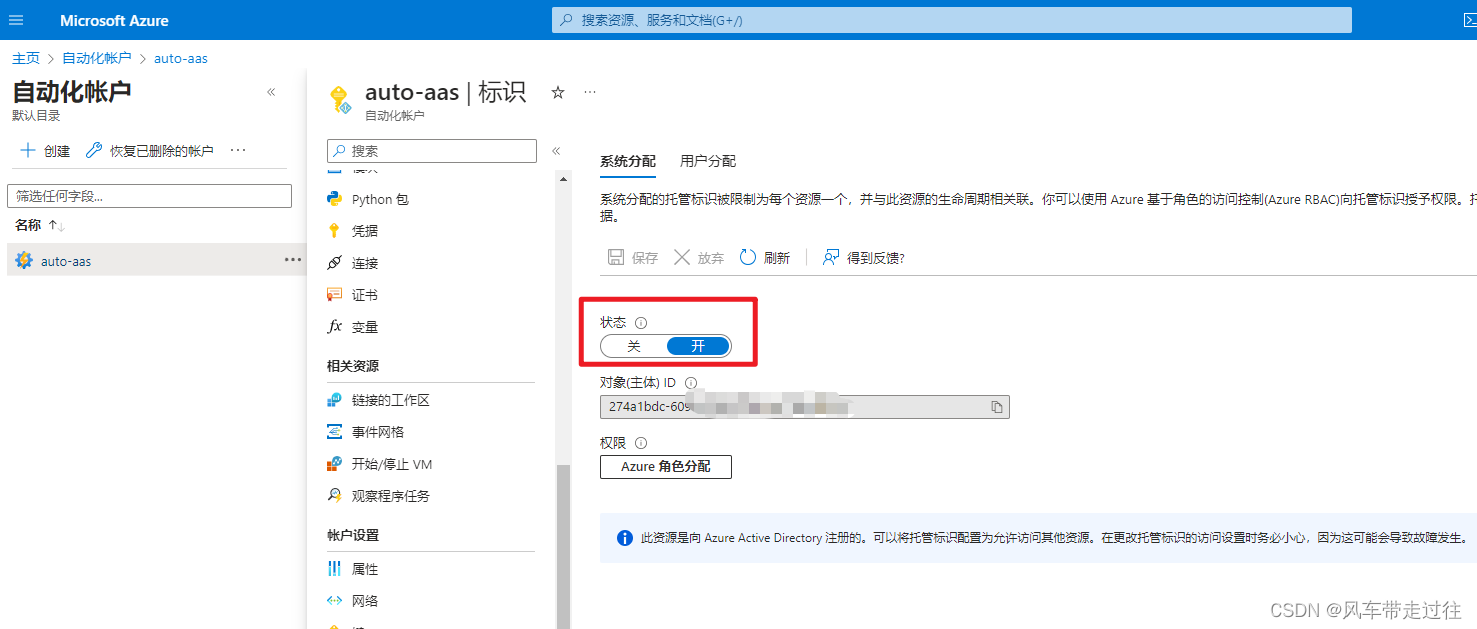
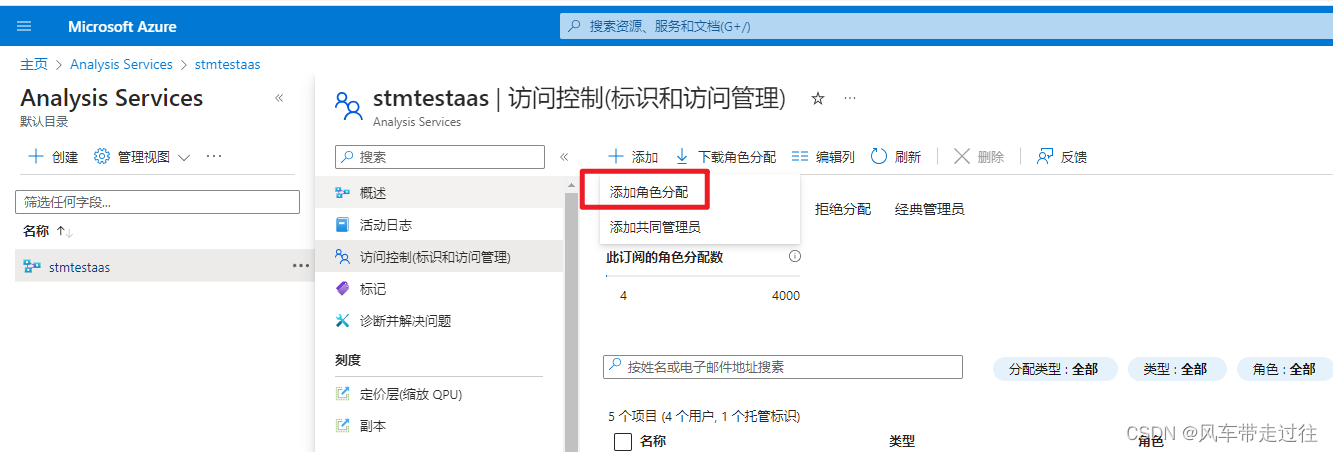
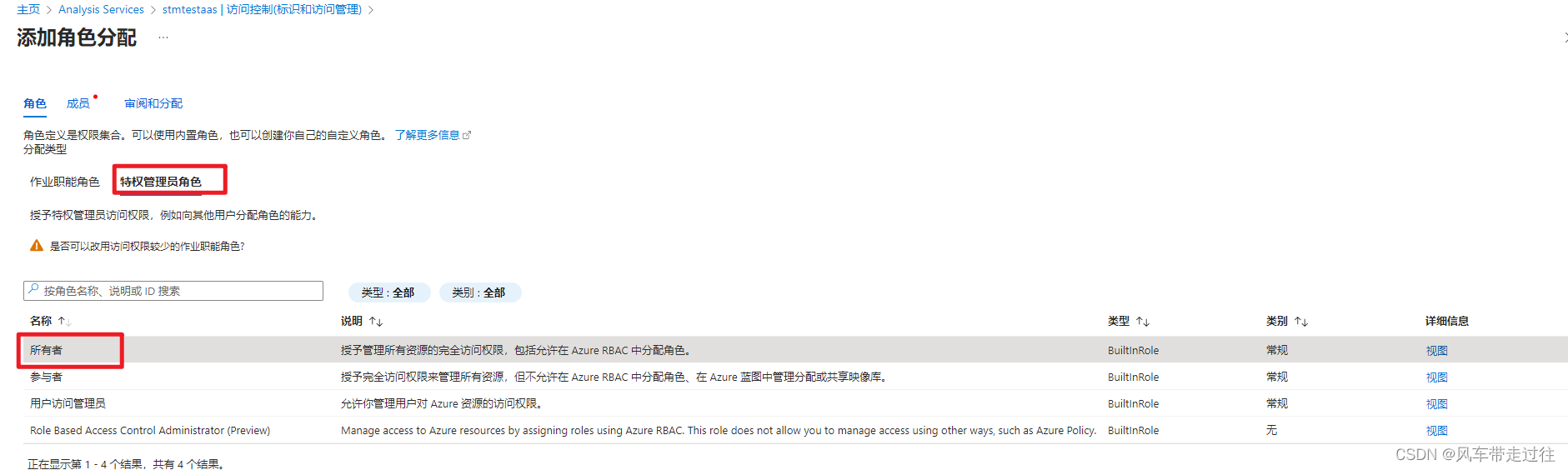
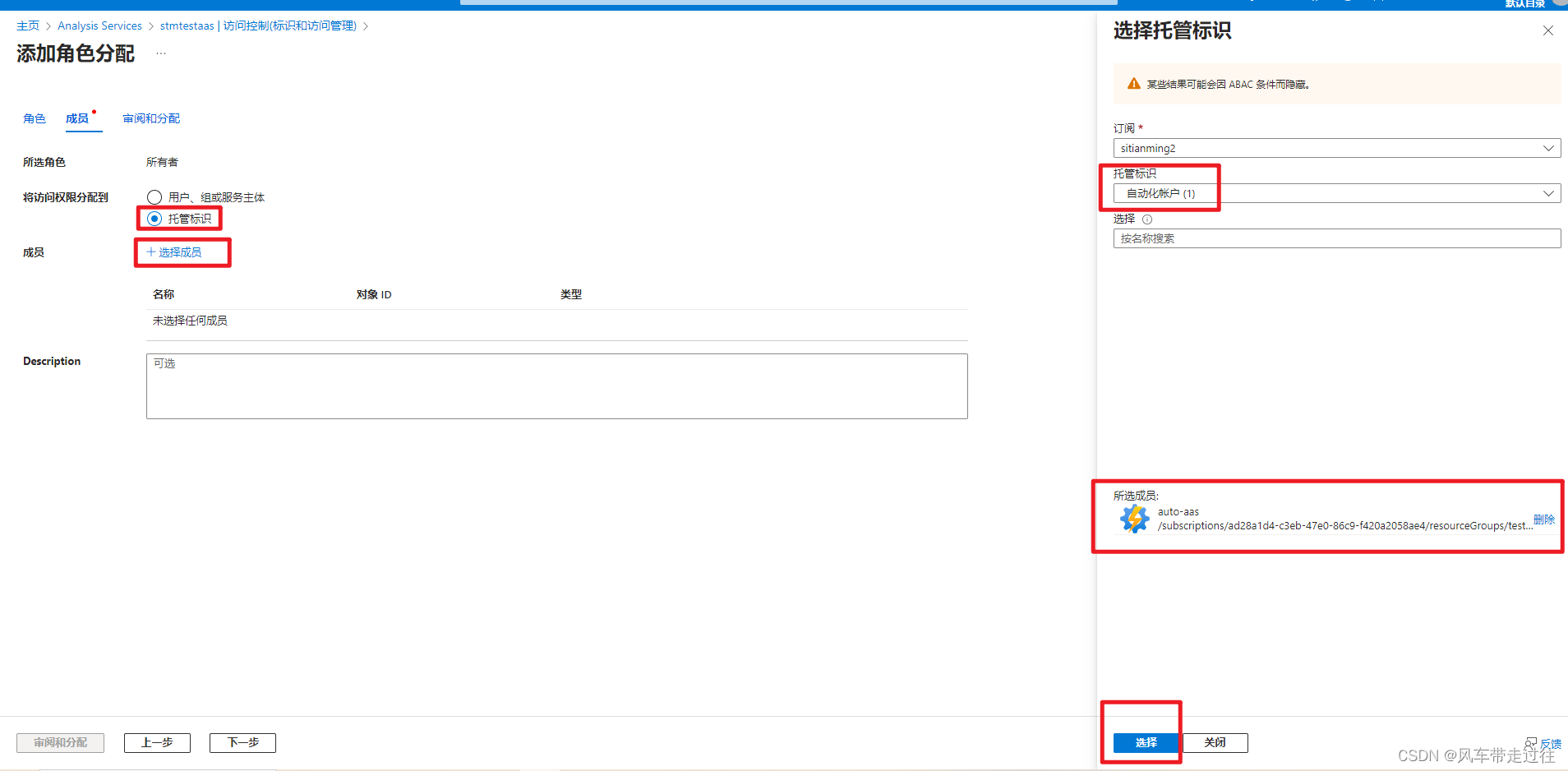
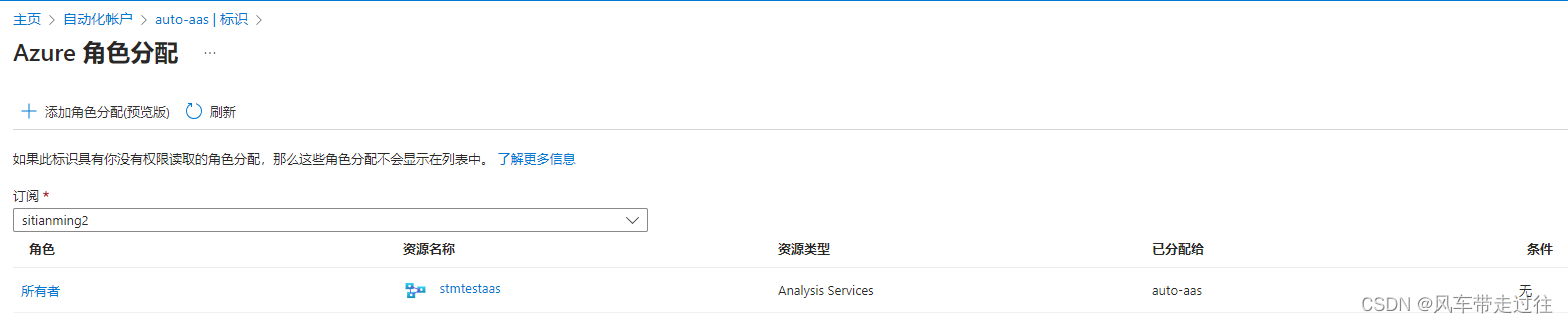
在Analysis Services中分配给标识所有者角色。
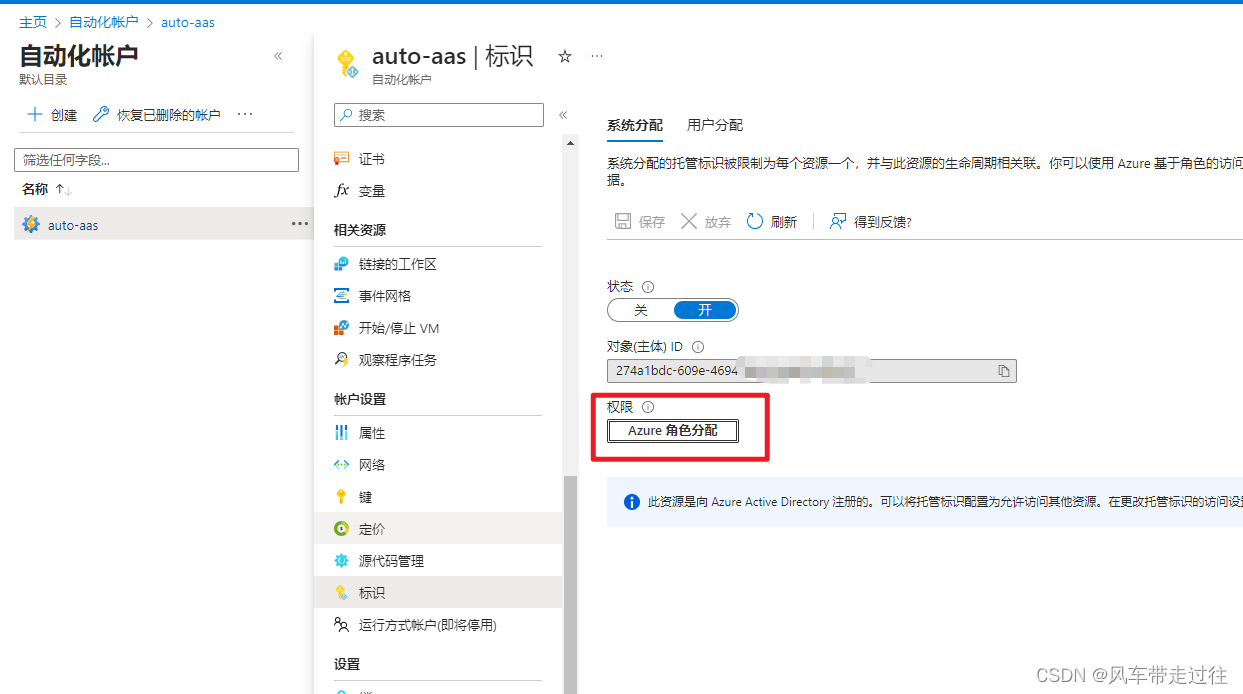
在自动化账户的标识处可以看到已分配的权限
添加runbook
S1为定价层
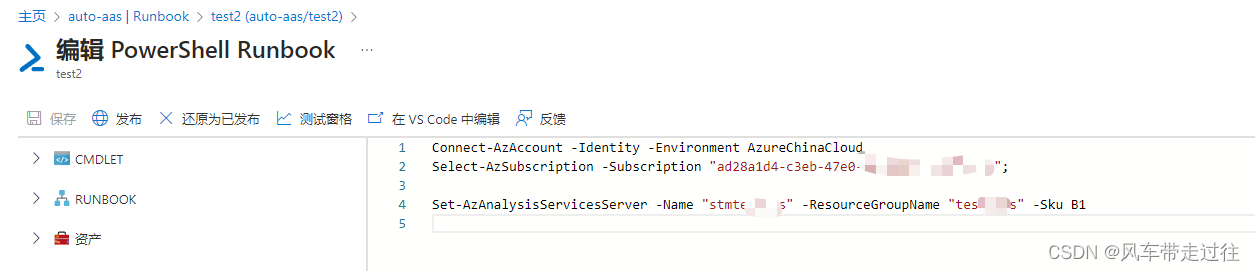
Connect-AzAccount -Identity -Environment AzureChinaCloud
Select-AzSubscription -Subscription "a81419be-xxxx-xxxx-950d-xxxxxxc9542e";Set-AzAnalysisServicesServer -Name "test" -ResourceGroupName "v5" -Sku S1
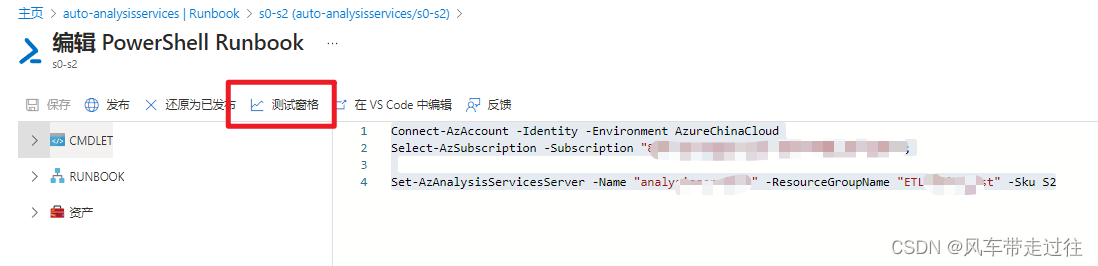
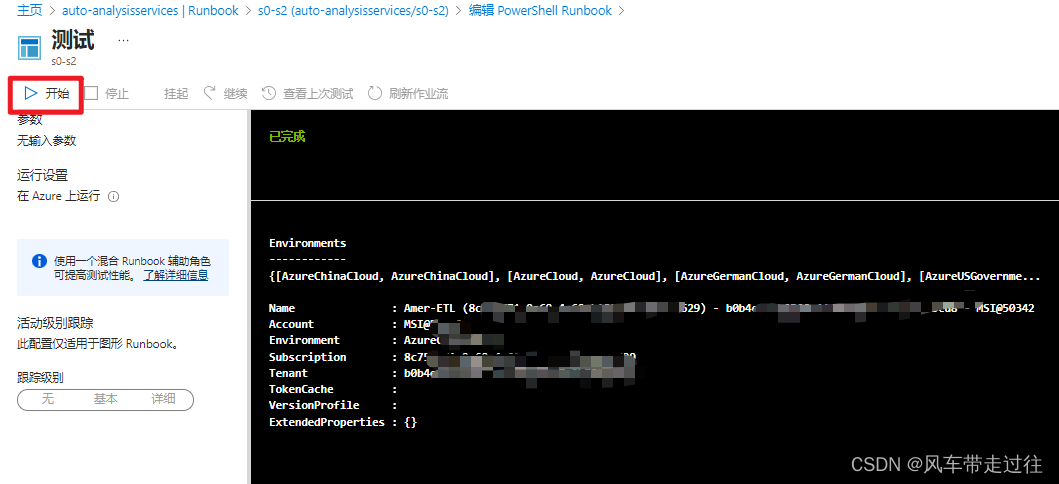
测试
自助排错
官方文档: https://docs.azure.cn/zh-cn/automation/troubleshoot/runbooks