如何能让企业做网站的打算dede网站栏目管理
目录
- Echarts中的地图组件
- 地图组件初体验
- 下载地图数据
- 准备Echarts的基本结构
- 导入地图数据并注册
- 展示地图数据
- 结合visualMap展示地图数据
Echarts中的地图组件
Echarts中的地图组件是一种用于展示地理数据的可视化组件。它可以显示全国、各省市和各城市的地图,并支持自定义地图展示。地图组件提供了丰富的配置项,包括地图的颜色、标注、图例、缩放、拖拽等,可以满足不同需求的数据可视化展示。在地图组件中,可以通过数据标记、热力图、散点图等方式展示数据,同时支持地图事件的监听和触发,如点击、鼠标移入移出等事件。
在Echarts中,使用地图组件需要引入地图数据,Echarts提供了全国、各省市和各城市的地图数据,同时也支持自定义地图展示。自定义地图需要提供地图的json数据,包括地图的各个区域的名称、坐标等信息。通过配置项中的geo属性,可以设置地图的名称、标注、颜色、缩放等属性。通过配置项中的series属性,可以设置地图数据的展示方式,如数据标记、热力图、散点图等。同时,地图组件还支持地图事件的监听和触发,如点击、鼠标移入移出等事件。
地图组件初体验
下载地图数据
在使用地图组件之前,需要先下载相应的地图数据。地图数据可以到下面的网址进行下载:https://datav.aliyun.com/portal/school/atlas/area_selector
准备Echarts的基本结构
新建MapChart.vue组件,引入Echarts,并在组件中新建div,组织Echarts的基本结构
<template><div ref="chart" style="width: 100%;height: 600px;"></div>
</template>
<script setup>
import * as echarts from 'echarts'
import { ref, onMounted, reactive } from 'vue'
const chart = ref(null)onMounted(() => {const myChart = echarts.init(chart.value)const option = {}myChart.setOption(option)
})
</script>
导入地图数据并注册
在MapChart.vue中导入我们上面下载的地图组件,
import cmap from '../assets/china.json'
使用echarts.registerMap()方法注册地图地图数据,通过该方法,我们可以将自定义的地图数据注册到Echarts中,以便在地图组件中使用。该方法的语法如下:
echarts.registerMap(mapName, geoJson, specialAreas?)
其中,参数说明如下:
mapName:地图名称,用于在地图组件中引用地图数据。geoJson:地图数据,可以是GeoJSON格式的字符串或对象,也可以是包含多个GeoJSON格式的数组。specialAreas(可选):特别地区的配置项,用于在地图中标注特别的区域,例如港澳台地区等。
使用该方法注册地图数据后,我们就可以在Echarts中使用该地图了
<template><div ref="chart" style="width: 100%;height: 600px;"></div>
</template>
<script setup>
import * as echarts from 'echarts'
import { ref, onMounted } from 'vue'
import cmap from '../assets/china.json'
const chart = ref(null)
// 注册中国地图数据
echarts.registerMap("china", cmap)
onMounted(() => {const myChart = echarts.init(chart.value)// 使用中国地图数据const option = {series: [{type: 'map',map: 'china'}]};myChart.setOption(option)
})
上述代码中,我们首先使用echarts.registerMap()方法注册了中国地图数据,然后在地图系列中使用map属性指定了地图名称为china。这样就可以在地图组件中展示中国地图了。
**注意:**我们在注册地图数据时定义的地图名称必须要和series中的map配置项的名称一致。
配置第三个参数: specialAreas(可选)特别地区配置项的示例:
// 注册中国地图数据
echarts.registerMap('china', chinaGeoJson, {'南海诸岛': { // 地区名称left: 123, // 地区位置,可以是数字、字符串或百分比top: 23,width: 10, // 地区大小,可以是数字或百分比height: 10}
});
上述代码中,我们在使用echarts.registerMap()方法注册中国地图数据时,还传入了一个特别地区的配置项。其中,南海诸岛 表示特别地区的名称,left和top表示特别地区在地图中的位置,width和height表示特别地区的大小。配置完成后效果如下图所示:
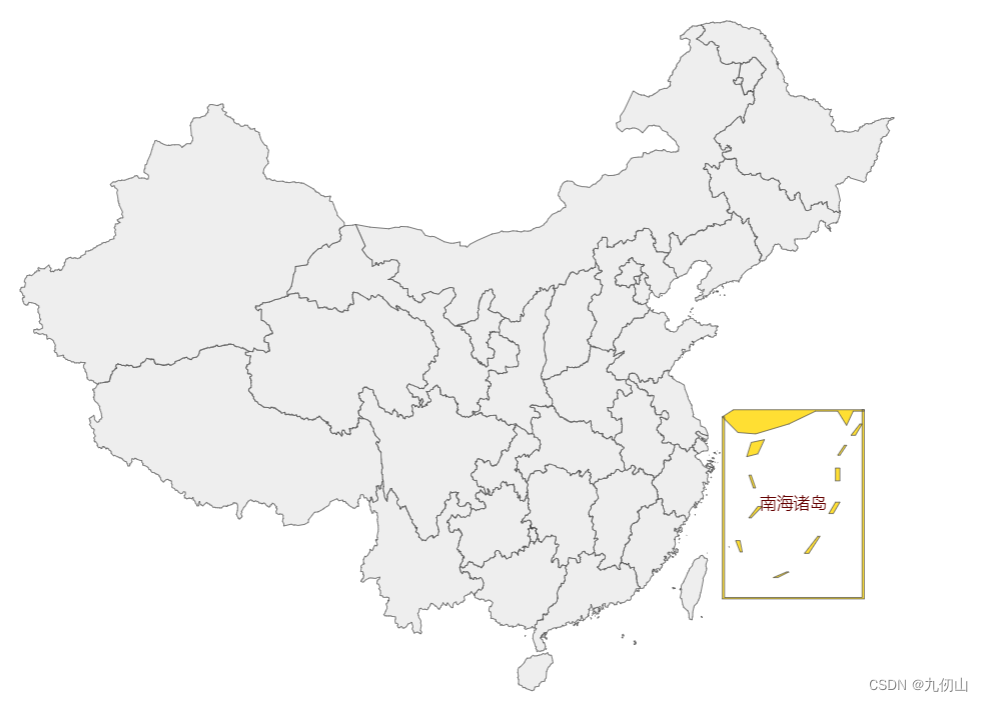
在实际使用中,我们可以根据需要自定义特别地区的配置项。
展示地图数据
经过上面的配置将地图加载成功后,就需要根据我们的业务逻辑将实际需要展示的数据展示到地图上了,这里我们随机给一些数据,同时在series中配置roam属性为true开启鼠标滚轮放大缩小功能;配置label使地图显示文字标签;
series: [{type: 'map',map: 'china', roam: true,//滚轮放大缩小label: {//显示文字标签show: true},data: [{ name: '北京', value: Math.round(Math.random() * 1000) },{ name: '天津', value: Math.round(Math.random() * 1000) },{ name: '上海', value: Math.round(Math.random() * 1000) },{ name: '重庆', value: Math.round(Math.random() * 1000) },{ name: '河北', value: Math.round(Math.random() * 1000) },{ name: '河南', value: Math.round(Math.random() * 1000) },{ name: '云南', value: Math.round(Math.random() * 1000) },{ name: '辽宁', value: Math.round(Math.random() * 1000) },{ name: '黑龙江', value: Math.round(Math.random() * 1000) },{ name: '湖南', value: Math.round(Math.random() * 1000) },{ name: '安徽', value: Math.round(Math.random() * 1000) },{ name: '山东', value: Math.round(Math.random() * 1000) },{ name: '新疆', value: Math.round(Math.random() * 1000) },{ name: '江苏', value: Math.round(Math.random() * 1000) },{ name: '浙江', value: Math.round(Math.random() * 1000) },{ name: '江西', value: Math.round(Math.random() * 1000) },{ name: '湖北', value: Math.round(Math.random() * 1000) },{ name: '广西', value: Math.round(Math.random() * 1000) },{ name: '甘肃', value: Math.round(Math.random() * 1000) },{ name: '山西', value: Math.round(Math.random() * 1000) },{ name: '内蒙古', value: Math.round(Math.random() * 1000) },{ name: '陕西', value: Math.round(Math.random() * 1000) },{ name: '吉林', value: Math.round(Math.random() * 1000) },{ name: '福建', value: Math.round(Math.random() * 1000) },{ name: '贵州', value: Math.round(Math.random() * 1000) },{ name: '广东', value: Math.round(Math.random() * 1000) },{ name: '青海', value: Math.round(Math.random() * 1000) },{ name: '西藏', value: Math.round(Math.random() * 1000) },{ name: '四川', value: Math.round(Math.random() * 1000) },{ name: '宁夏', value: Math.round(Math.random() * 1000) },{ name: '海南', value: Math.round(Math.random() * 1000) },{ name: '台湾', value: Math.round(Math.random() * 1000) },{ name: '香港', value: Math.round(Math.random() * 1000) },{ name: '澳门', value: Math.round(Math.random() * 1000) }]}]
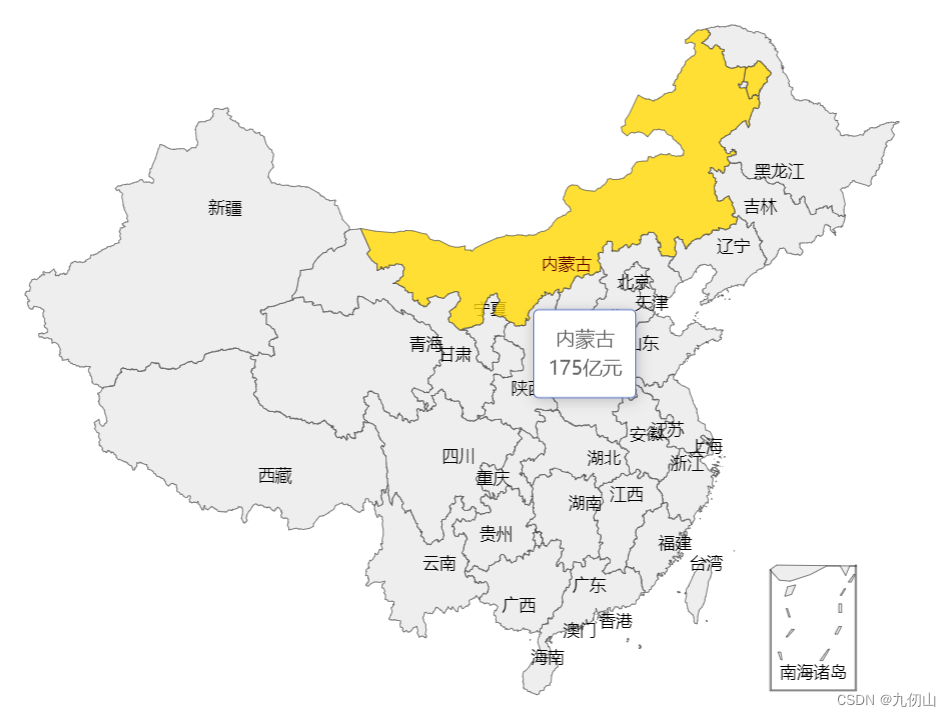
这样定义完成后,文字标签和鼠标的滚轮效果已经可以看到了,但是我们添加的数据还没有看到,这时我们可以添加tooltip配置项,使其在鼠标经过是弹出提示框
tooltip: {trigger: 'item',formatter: '{b}<br/>{c}亿元'
},
刷新浏览器,可以看到数据已经在提示框中显示了
结合visualMap展示地图数据
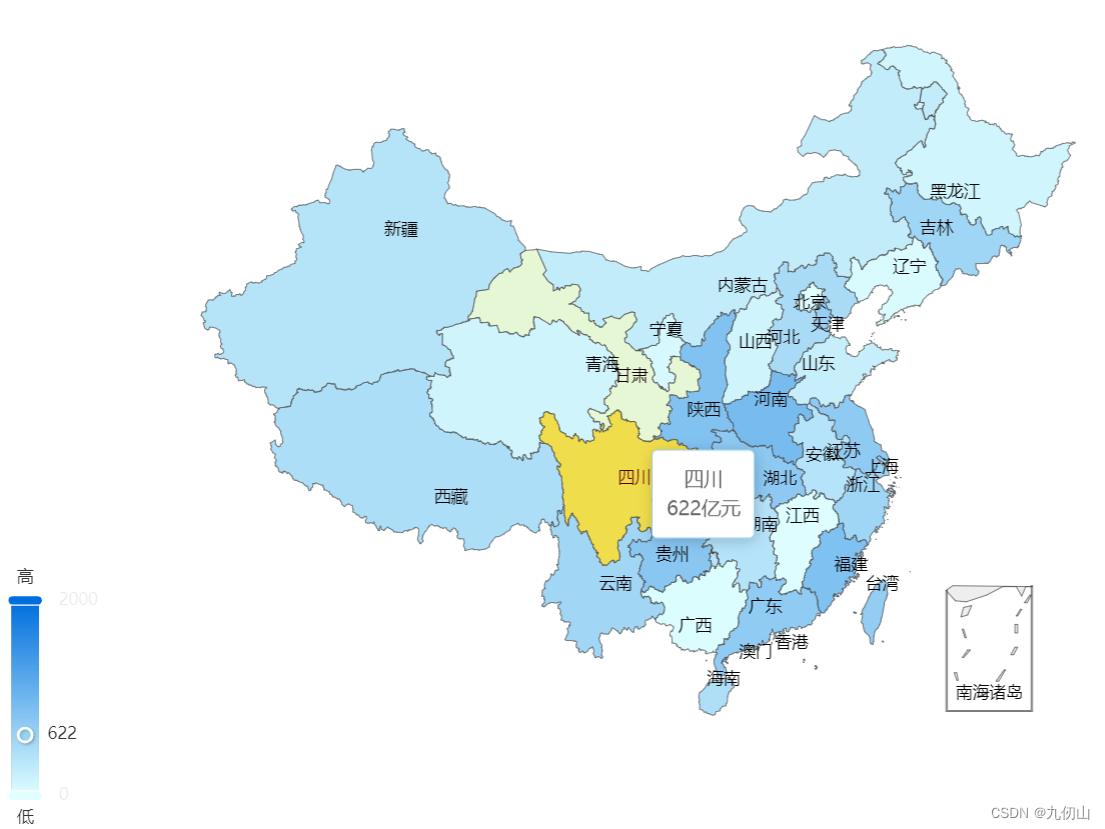
在实际的开发中我们往往会结合visualMap来展示地图数据的层级,视觉映射组件 visualMap可以将数据的大小和颜色映射到地图上,从而实现地图的数据可视化。在上面的代码中,添加visualMap配置项,代码如下:
visualMap: {min: 0,max: 2000,left: 'left',top: 'bottom',text: ['高', '低'],calculable: true,inRange: {color: ['#e0ffff', '#006edd']}},
在上面的代码中,我使用了 visualMap 组件来将数据的大小映射到地图上,同时设置了 inRange 属性来定义数据映射的颜色范围。
可以看到,地图根据我们上面的数据大小显示了不同的颜色层级
OK,今天时间太晚了,关于Echarts中地图的使用方法,就先聊到这里,下次咱们接着聊,喜欢的小伙伴点赞关注加收藏哦!