网站网址正能量wordpress 评论 原理
Python 中的条件语句是通过一条或多条语句的执行结果(True 或者 False)来决定执行的代码块。
它的一般格式为:if...elif...else
if condition1: #条件1CodeBlock1 #代码块1
elif condition2:CodeBlock2
else:CodeBlock3如果condition1成立,那么执行CodeBlock1;否则如果condition2成立,则执行CodeBlock2;否则执行CodeBlock3
下面是两个简单的例子
#输入成绩,输出等级
a=input('请输入你的成绩:')
a=float(a)
if a==100:print('你的成绩等级为A+')
elif a>=80 and a<100:print('你的成绩等级为A')
elif a>=60 and a<80:print('你的成绩等级为B')
elif a>=0 and a<60:print('你的成绩不及格')
else:print('输入数据错误,请重新输入')
但是我们要特别注意:写条件时,要注意条件之间是否有包含关系,以及条件的顺序,例如:
#输入成绩,输出等级
a=input('请输入你的成绩:')
a=float(a)
if a>=60:print('你的成绩等级为C')
elif a>=80:print('你的成绩等级为B')
elif a>90:print('你的成绩等级为A')
elif a==100:print('你的成绩等级为A+')
else:print('输入数据错误,请重新输入')输入80的时候,结果如下:

很明显,这不是我们想要的结果
#数字猜谜游戏
num=random.randint(1,100)
i=0
while True:print('请输入一个0到100的数据:', end='')numinput = input()numinput=int(numinput)i=i+1if numinput>num:print('猜大了,往小了猜')elif numinput<num:print('猜小了,往大了猜')else:print('猜对啦')print('您一共猜了%d次'%i)exit()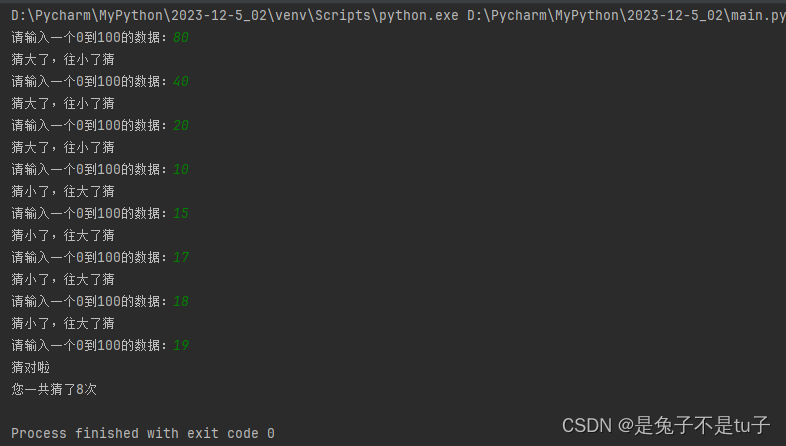
match...case(在python3.10版本中增加,类似C语言中的switch...case语句)
它的一般格式为:
match subject:case <pattern_1>:<action_1>case <pattern_2>:<action_2>case <pattern_3>:<action_3>case _:<action_wildcard>case _: 类似于 C 和 Java 中的 default:,当其他 case 都无法匹配时,匹配这条,保证永远会匹配成功。
一个例子如下:
def http_error(status):match status:case 400:return "Bad request"case 404:return "Not found"case 418:return "I'm a teapot"case _:return "Something's wrong with the internet"mystatus=400
print(http_error(400))结果为:
Bad request
一个 case 也可以设置多个匹配条件,条件使用 | 隔开,例如:
...case 401|403|404:return "Not allowed"