江苏省住房和建设部网站首页自己建设个人网站要花费多少
目录
第三章 现代密码学应用案例
3.1安全电子邮件方案
3.1.1 PGP产生的背景
3.2 PGP提供了一个安全电子邮件解决方案
3.2.1 PGP加密流程
3.2.2 PGP解密流程
3.2.3 PGP整合了对称加密和公钥加密的方案
3.3 PGP数字签名和Hash函数
3.4 公钥分发与认证——去中心化模型
模型一:金字塔模型
模型二:信任网络
第三章 实验
1.生成密钥对
2.交换各自公钥
3.邮件发送与接收
第三章 现代密码学应用案例
3.1安全电子邮件方案
3.1.1 PGP产生的背景
你的电子邮件不安全,电子邮件在传输中使用的SMTP协议。
- 无法保证邮件在传输过程中不被人偷看。
- 无法确认来源。
- 无法确定邮件是否在传输过程中被篡改
- 当邮件被发到错误地址,可能造成信息泄露
3.2 PGP提供了一个安全电子邮件解决方案
PGP (Pretty Good Privacy) 具有以下的功能
- 消息加密
- 数字签名
- 完整性确认
- 数据压缩
3.2.1 PGP加密流程
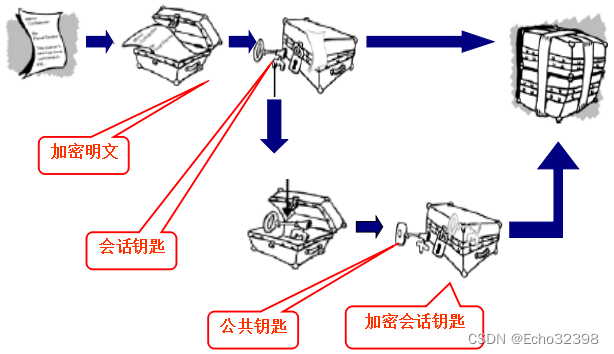
3.2.2 PGP解密流程

3.2.3 PGP整合了对称加密和公钥加密的方案
- 保持了对称加密算法速度快的特点
- 具有公钥算法密钥分配方便的特点
3.3 PGP数字签名和Hash函数
PGP数字签名:私钥签名,公钥验证签名
直接对明文进行数字签名一些问题
- 速度非常慢
- 生成大量的数据
PGP的解决方案
- 对明文使用一种Hash函数, 产生定长的数据, 称为消息摘要
- PGP使用签名算法对摘要签名
- PGP将签名和明文一同传输.

3.4 公钥分发与认证——去中心化模型
模型一:金字塔模型
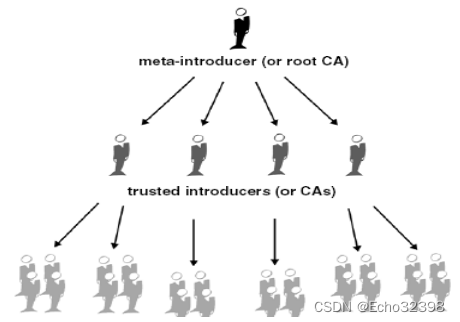
模型二:信任网络
第一步:人与人直接信任(建立信任)
第二步:以直接信任为基础,生成信任网络
第三章 实验
1.生成密钥对
文件->新建用户->按照提示输入,点击下一步即可

2.交换各自公钥
导出公钥:右键点击导出->填入文件名(如果只交换公钥,去掉私钥即可)
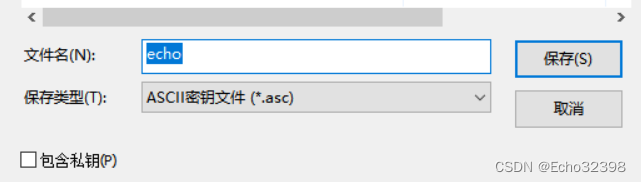
导入其他人的公钥:点击文件导入即可
3.邮件发送与接收
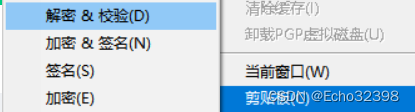
发送方加密签名邮件,接收方解密与验证邮件
邮件内容加密并剪切(发送方的口令)->发送
邮件内容解密(接收方的口令)->解密成功