纪检网站建设方案图片动画制作
1.6 C语言之数组概述
- 一、数组
- 二、练习
一、数组
所谓数组,就是内存中一片连续的空间,可以用来存储一组同类型的数据
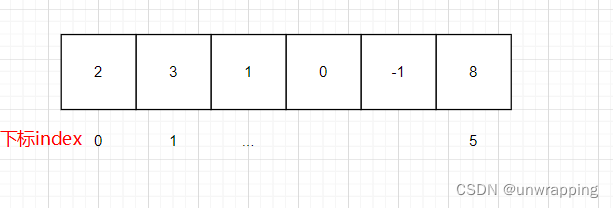
数组有下标,从0开始,可以理解为是给数组中的元素编号,便于后续寻址访问
我们来编写一个程序,统计所有输入中,0-9这几个数字出现的次数
先定义一个数组,数组总共有10个元素,用于存放0-9的出现次数,而0-9可以使用数组的下标表示
#include <stdio.h>// 编写一个程序,统计所有输入中,0-9这几个数字出现的次数
main()
{int c;int ndigit[10]; // 声明数组// 初始化数组,将数组中所有元素都置为0for (int i = 0; i < 10;++i)ndigit[i] = 0; // 在每次执行的时候,可以把ndigit[i]理解成一个int变量while ((c = getchar()) != EOF){if (c >= '0' && c <= '9')// 如果输入的是0-9的数字,则给对应下标的元素加1,比如,输入'2', 那么对应 ndigit[2-0]++ndigit[c - '0'];}// 打印输出数组printf("0-9数组元素\n");for (int i = 0; i < 10;++i)printf("数字:%d 输入的次数: %d\n", i, ndigit[i]);
}
- int ndigit[10]; 将变量ndigit声明为由10个整型数构成的数组。在C语言中,数组下标总是从0开始,因此该数组的10个元素分别是
ndigit[0], ndigit[1], ndigit[2], …, ndigit[9] - 数组下标可以是任何整型表达式,包括整型变量(i)以及整型常量,比如c - ‘0’就是一个整型表达式,如果输入的字符是’0’-‘9’,那么对应的整数值也是0-9,刚好满足数组的下标取值
二、练习
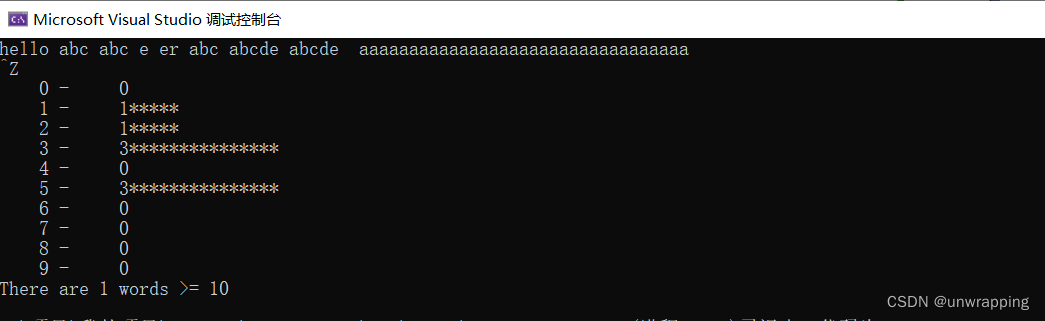
- 编写一个程序,打印输入中单词长度的直方图。水平方向的直方图比较容易绘制,垂直方向的直方图则要困难些
注意:长度为3的单词有3个;长度为5的单词有5个,直方图体现每个长度的数量即可
水平方向:
#include <stdio.h>
#define OUT_WORD 1 // 不在单词中,遇到空格、换行符、制表符,state设置成 OUT_WORD
#define IN_WORD 0 // 在单词中,遇到单词的第一个字符时,state设置成 IN_WORD
#define MAX_WORD 10 /* max length of a word*/
#define MAX_HIST 15// 编写一个程序,打印输入中单词长度的直方图。
main()
{int c, nc, state;int len; /* length of each bar */int maxValue; /* maximum value for wl[] */int ovflow; /* number of overflow words */int wl[MAX_WORD]; /* world length counters */state = OUT_WORD; // 初始值,不在单词中nc = 0; /* number of chars in a word */ovflow = 0; /* number of words >= MAX_WORD */// 初始化数组for (int i = 0; i < MAX_WORD;++i)wl[i] = 0;// 输入字符,统计while ((c = getchar()) != EOF){if (c == ' ' || c == '\n' || c == '\t') {state = OUT_WORD;if (nc > 0)if (nc < MAX_WORD)++wl[nc]; // 统计小于最大单词长度限制的单词长度else++ovflow; // 超出最大单词长度限制的单词的数量nc = 0; // 单词长度置0,下一个单词重新计数}else if (state == OUT_WORD) {state = IN_WORD;nc = 1;}else++nc;}maxValue = 0; // 找出所有单词中最大长度for (int i = 0; i < MAX_WORD;++i){if (wl[i] >= maxValue) {maxValue = wl[i];}}for (int i = 0; i < MAX_WORD;++i){printf("%5d - %5d", i, wl[i]);if (wl[i] > 0) {// 计算len, len对应直方图的长度,wl[i] * MAX_HIST / maxValue // 这个公式可以保证单词长度数量最多的直方图最大是15,其他数量的长度则按比例取,// 比如数量最多的单词长度是5,总共有3个,那么len = 3 * 15/3; 而长度为1的单词有1个,则len = 1*15/3if ((len = wl[i] * MAX_HIST / maxValue) <= 0)len = 1;}elselen = 0;while (len > 0) {putchar('*');--len;}putchar('\n');}if (ovflow > 0)printf("There are %d words >= %d\n", ovflow, MAX_WORD);
}
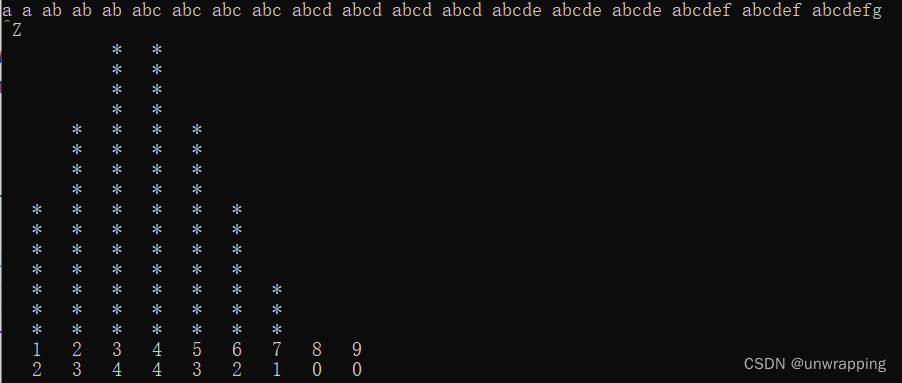
垂直方向:
#include <stdio.h>
#define OUT_WORD 1 // 不在单词中,遇到空格、换行符、制表符,state设置成 OUT_WORD
#define IN_WORD 0 // 在单词中,遇到单词的第一个字符时,state设置成 IN_WORD
#define MAX_WORD 10 /* max length of a word*/
#define MAX_HIST 15// 编写一个程序,打印输入中单词长度的直方图。
main()
{int c, nc, state;int maxValue; /* maximum value for wl[] */int ovflow; /* number of overflow words */int wl[MAX_WORD]; /* world length counters */state = OUT_WORD; // 初始值,不在单词中nc = 0; /* number of chars in a word */ovflow = 0; /* number of words >= MAX_WORD */// 初始化数组for (int i = 0; i < MAX_WORD;++i)wl[i] = 0;// 输入字符,统计while ((c = getchar()) != EOF){if (c == ' ' || c == '\n' || c == '\t') {state = OUT_WORD;if (nc > 0)if (nc < MAX_WORD)++wl[nc]; // 统计小于最大单词长度限制的单词长度else++ovflow; // 超出最大单词长度限制的单词的数量nc = 0; // 单词长度置0,下一个单词重新计数}else if (state == OUT_WORD) {state = IN_WORD;nc = 1;}else++nc;}maxValue = 0; // 找出所有单词中最大长度for (int i = 1; i < MAX_WORD;++i){if (wl[i] >= maxValue) {maxValue = wl[i];}}// 从上往下一行一行打印for (int i = MAX_HIST; i > 0; --i) {// 每行,从左往右打印,如果需要打印则打印' *', 如果不需要打印,则打印" ";for (int j = 1; j < MAX_WORD;++j) {if (wl[j] * MAX_HIST / maxValue >= i)printf(" *");else printf(" ");}putchar('\n');}for (int i = 1; i < MAX_WORD;++i)printf("%4d", i);printf("\n");for (int i = 1; i < MAX_WORD;++i)printf("%4d", wl[i]);printf("\n");if (ovflow > 0)printf("There are %d words >= %d\n", ovflow, MAX_WORD);
}
- 编写一个程序,打印输入中各个字符出现频度的直方图
#include <stdio.h>
#define MAX_CHAR 128 /* max number of chars*/
#define MAX_HIST 15
// 编写一个程序,打印输入中各个字符出现频度的直方图
main()
{int c, len, max;int chars[MAX_CHAR];for (int i = 0; i < MAX_CHAR; ++i)chars[i] = 0;while ((c = getchar()) != EOF) {if (c > 0 && c < MAX_CHAR) {++chars[c];}}max = 0;for (int i = 0; i < MAX_CHAR; i++) {if (chars[i] >= max)max = chars[i];}for (int i = 0; i < MAX_CHAR; i++) {printf("%d-%d", i, chars[i]);len = chars[i] * MAX_HIST / max;while (len > 0) {putchar('*');--len;}putchar('\n');}
}