甘肃建设项目公示网站巩义旅游网站设计公司
C# 实现 国密SM4/ECB/PKCS7Padding对称加密解密,为了演示方便本问使用的是Visual Studio 2022 来构建代码的
1、新建项目,之后选择 项目 鼠标右键选择 管理NuGet程序包管理,输入 BouncyCastle 回车 添加BouncyCastle程序包

2、代码如下:CBC模式
byte[] plaintext = Encoding.UTF8.GetBytes("1234567890国abcdefghijklmnopqrstuvwxyz");byte[] keyBytes = Encoding.UTF8.GetBytes("1234567890123456");byte[] iv = Encoding.UTF8.GetBytes("0123456789ABCDEF");// SM4/CBC加密KeyParameter key = ParameterUtilities.CreateKeyParameter("SM4", keyBytes);ParametersWithIV keyParamWithIv = new ParametersWithIV(key, iv);IBufferedCipher inCipher = CipherUtilities.GetCipher("SM4/CBC/PKCS7Padding");inCipher.Init(true, keyParamWithIv);byte[] cipher = inCipher.DoFinal(plaintext);//Console.WriteLine("加密后的密文(hex): {0}", BitConverter.ToString(cipher, 0).Replace("-", string.Empty));rtbCard.Text = $"加密后的密文: {Convert.ToBase64String(cipher).Replace("-", string.Empty)}";// SM4/CBC解密inCipher.Reset();inCipher.Init(false, key);byte[] bin = inCipher.DoFinal(cipher);string ans = Encoding.UTF8.GetString(bin);//Console.WriteLine("解密后的密文(hex): {0}", Convert.ToBase64String(cipher).Replace("-", string.Empty));//Console.WriteLine("解密明文内容: {0}\t是否匹配: {1}", ans, Enumerable.SequenceEqual(plaintext, bin));rtbCard.Text = rtbCard.Text + "\r\n" + $"解密明文内容: {ans}\t是否匹配: {Enumerable.SequenceEqual(plaintext, bin)}";代码如下:ECB模式
byte[] plaintext = Encoding.UTF8.GetBytes("1234567890国abcdefghijklmnopqrstuvwxyz");byte[] keyBytes = Encoding.UTF8.GetBytes("1234567890123456");byte[] iv = Encoding.UTF8.GetBytes("0123456789ABCDEF");// SM4/ECB加密KeyParameter key = ParameterUtilities.CreateKeyParameter("SM4", keyBytes);//ParametersWithIV keyParamWithIv = new ParametersWithIV(key, iv);ParametersWithIV keyParamWithIv = new ParametersWithIV(key, iv);//IBufferedCipher inCipher = CipherUtilities.GetCipher("SM4/CBC/PKCS7Padding");IBufferedCipher inCipher = CipherUtilities.GetCipher("SM4/ECB/PKCS7Padding");//inCipher.Init(true, keyParamWithIv);inCipher.Init(true, key);byte[] cipher = inCipher.DoFinal(plaintext);//Console.WriteLine("加密后的密文(hex): {0}", BitConverter.ToString(cipher, 0).Replace("-", string.Empty));rtbCard.Text = $"加密后的密文: {Convert.ToBase64String(cipher).Replace("-", string.Empty)}";// SM4/ECB解密inCipher.Reset();//inCipher.Init(false, keyParamWithIv);inCipher.Init(false, key);byte[] bin = inCipher.DoFinal(cipher);string ans = Encoding.UTF8.GetString(bin);Console.WriteLine("解密后的密文(hex): {0}", Convert.ToBase64String(cipher).Replace("-", string.Empty));Console.WriteLine("解密明文内容: {0}\t是否匹配: {1}", ans, Enumerable.SequenceEqual(plaintext, bin));rtbCard.Text = rtbCard.Text + "\r\n" + $"解密明文内容: {ans}\t是否匹配: {Enumerable.SequenceEqual(plaintext, bin)}"; 3、运行

4、SM4密码算法是一个分组算法。数据分组长度为128比特,密钥长度为128 比特。加密算法采用32 轮迭代结构,每轮使用一个轮密钥。我们在实现可用data字节的形式,即秘钥Data为16位,加密数据Data需为16的整数倍,这两点很重要。
1、ECB模式
观察第一块,和第三块,皆为明文块0,相同的输入产生相同的输出

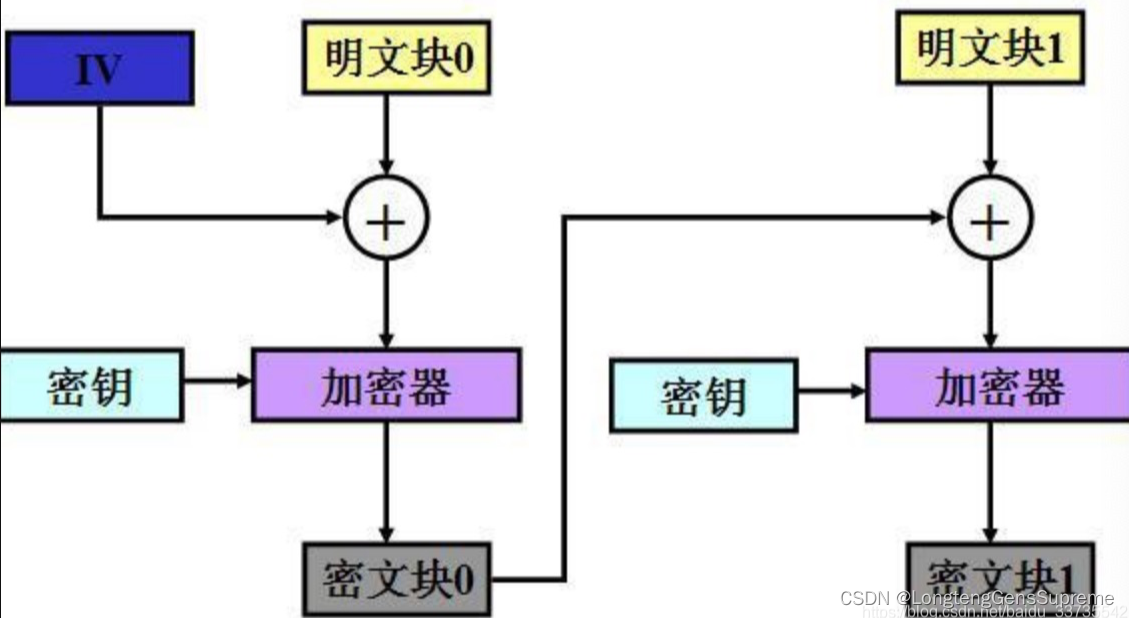
2、CBC模式
CBC(密文分组链接方式),它的实现机制使加密的各段数据之间有了联系。
也是按照data 16位来分组,第一组数据与初始化向量IV异或后的结果进行加密,密得到第一组密文C1(初始化向量I为全零),第二组数据与第一组的加密结果C1异或以后的结果进行加密,得到第二组密文C2...... 最后C1C2C3......Cn即为加密结果。此种方法安全性高,但是不利于并行计算,有误差传递,需要初始化向量IV。
参考链接:国密sm4 ECB、CEC模式探究与在iOS中的应用_sm4 ecb_落尘修竹的博客-CSDN博客