网店推广的方法国外seo做的好的网站
一.进程创建fork
见上篇文章
二.进程的终止
1.进程退出场景
1.代码运行完毕,结果正确,通过main函数退出码返回一般为0。
2.代码运行完毕,结果不正确,通过不同的退出码标识不同的错误原因。
3.代码异常终止(信号)。
strerror(错误码),将退出码转化为错误原因的字符
2.如何终止一个进程
exit()函数(c语言提供的)
void exit(int status)
在任何地方调用都表示直接终止进程
_exit()函数(系统调用接口)
相较于exit()不会执行用户定义的清理函数,不会冲刷缓冲区,直接退出
main()函数中的 return语句
return是一种更常见的退出进程方法。执行return n等同于执行exit(n),因为调用main的运行时函数会将main的返回值当做 exit的参数。
三.进程等待
wait()
#include<sys/types.h>
#include<sys/wait.h>
pid_t wait(int*status);
返回值:成功返回被等待进程pid,失败返回-1。
参数:输出型参数,获取子进程退出状态,不关心则可以设置成为NULL
waitpid()
pid_t waitpid(pid_t pid, int *status, int options);
返回值: 当正常返回的时候waitpid返回收集到的子进程的进程ID; 如果设置了选项WNOHANG,而调用中waitpid发现没有已退出的子进程可收集,则返回0; 如果调用中出错,则返回-1,这时errno会被设置成相应的值以指示错误所在;
参数:Pid=-1,等待任一个子进程,与wait等效。 Pid>0.等待其进程ID与pid相等的子进程。 status: WIFEXITED(status): 若为正常终止子进程返回的状态,则为真。(查看进程是否是正常退出) WEXITSTATUS(status): 若WIFEXITED非零,提取子进程退出码。(查看进程的退出码) options: WNOHANG: 若pid指定的子进程没有结束,则waitpid()函数返回0,不予以等待。若正常结束,则返回该子进程的ID。
输出型参数status
按照比特为的方式划分,有32位,我们只学习16位。
次低8位:子进程的退出码
(status>>8)&0xFF
低7位:子进程收到的信号编号
status&0x7F
本质是父进程调用系统接口去拿子进程task_struct中的退出码和退出信号,由于进程具有独立性,定义全局变量无法获取。因为全局变量属于父进程,子进程想写入会发生写时拷贝
第8位:coredump标志位
进行位运算过于复杂,操作系统为我们提供了两个宏
if(WIFEXITED(status))printf("%d",WEXITSTATUS(status));
非阻塞等待
waitpid()第三个options参数如果为0,则默认为阻塞等待,若设置为宏定义WNOHANG,则为非阻塞等待。
什么是非阻塞等待?
父进程通过操作系统检测子进程状态,如果退出了就接收到子进程的退出信息。如果检测到没退出,且options等于0就挂起父进程,在等待队列中阻塞等待子进程退出(在内核中阻塞被唤醒),这是阻塞等待。相反,如果options等于WNOHANG,发现没有子进程退出,那么直接返回0不会阻塞等待子进程退出,而是采用非阻塞的轮询检测的方式
四.进程的程序替换
通过特定接口,加载磁盘上的一个全新的程序(代码和数据),加载到调用进程的地址空间中,修改页表和物理地址的映射关系,以达到让子进程执行一个全新程序的目的。
原理
exec函数替换程序后进程的pid没有改变,只是将磁盘数据加载到物理内存后,重新建立页表和物理内存的映射关系,替换成功后原程序后续代码都不执行了(替换失败后续代码仍执行)。
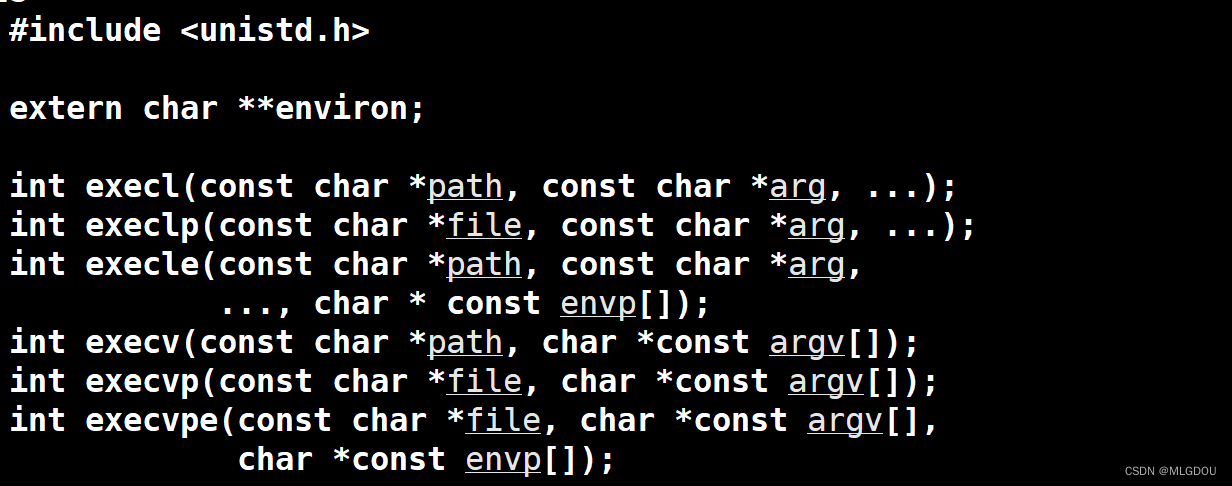
注意arg都要以null结尾,exec功能其实就是加载器的底层接口。

举例
int main()
{
char *const argv[] = {"ps", "-ef", NULL};
char *const envp[] = {"PATH=/bin:/usr/bin", "TERM=console", NULL};
execl("/bin/ps", "ps", "-ef", NULL);
// 带p的,可以使用环境变量PATH,无需写全路径
execlp("ps", "ps", "-ef", NULL);
// 带e的,需要自己组装环境变量
execle("ps", "ps", "-ef", NULL, envp);
execv("/bin/ps", argv);
// 带p的,可以使用环境变量PATH,无需写全路径
execvp("ps", argv);
// 带e的,需要自己组装环境变量
execve("/bin/ps", argv, envp);
上述接口都是系统提供的封装,实际系统调用的是execve
