网站安全管理网站开发备案费用
(物理:求出跑道长度)假设一个飞机的加速度是a而起飞速度是v,那么可以使用下
面的公式计算出飞机起飞所需的最短跑道长度:

编写程序,提示用户输入以米/秒(m/s)为单位的速度v和以米/秒的平方(m/s)为单
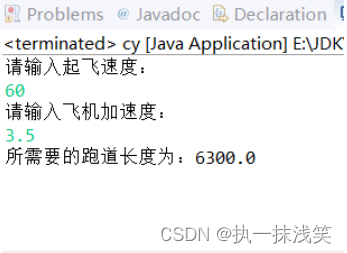
位的加速度 a,然后显示最短跑道长度。下面是一个运行示例:

package myjava;
import java.math.*;
import java.util.Scanner;
public class cy {public static void main(String[]args){float v,a,s;Scanner input = new Scanner(System.in);System.out.println("请输入起飞速度:");v=input.nextFloat();System.out.println("请输入飞机加速度:");a=input.nextFloat();s=v*v/2*a;System.out.println("所需要的跑道长度为:"+s);}
}运行结果: