ps软件网站有哪些功能wordpress 百度文库
2017年9月,W3C发布媒体查询(Media Query Level 4)候选推荐标准规范,它扩展了已经发布的媒体查询的功能。该规范用于CSS的@media规则,可以为文档设定特定条件的样式,也可以用于HTML、JavaScript等语言。
1、媒体查询基础
媒体查询可以根据设备特性,如屏幕宽度、高度、设备方向(横向或纵向),为设备定义独立的CSS样式表。一个媒体查询由一个可选的媒体类型和零个或多个限制范围的表达式组成,如宽度、高度和颜色。
1.1、媒体类型和媒体查询
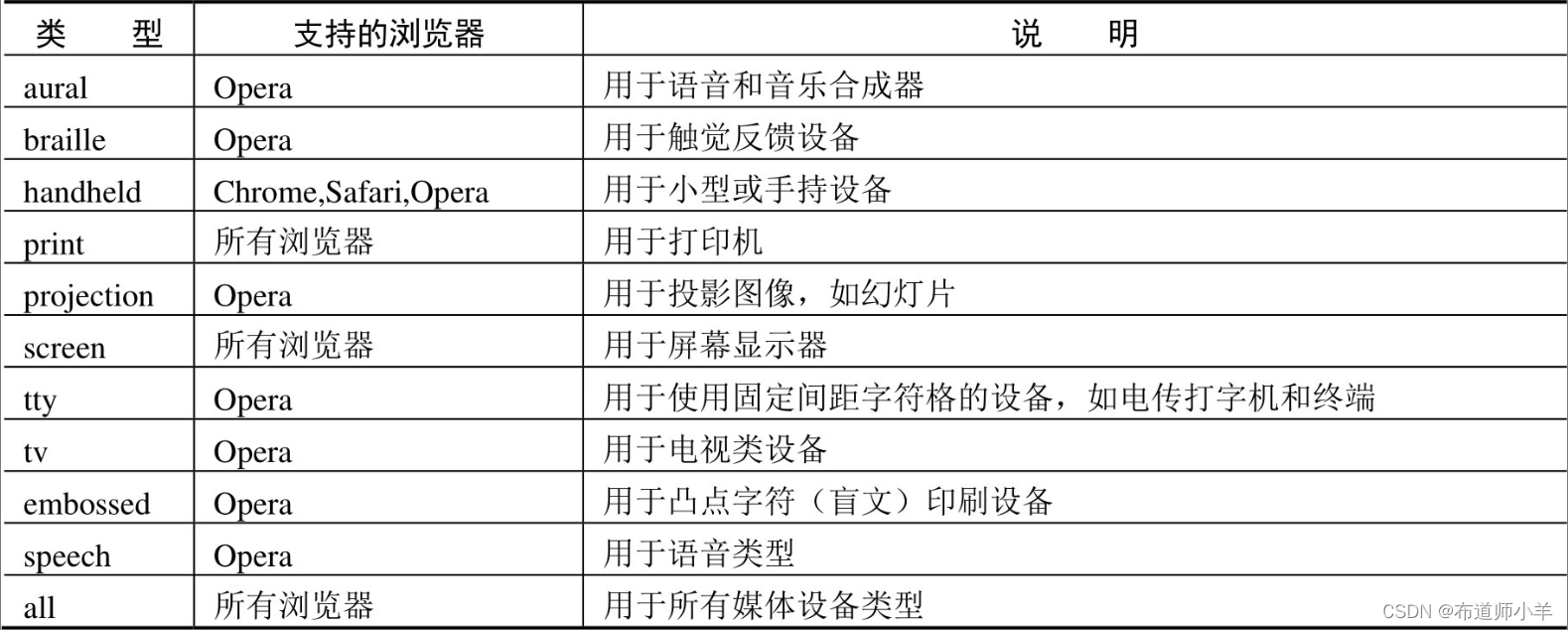
CSS2提出媒体类型(Media Type)的概念,它允许为样式表设置限制范围的媒体类型。例如,仅供打印的样式表文件、仅供手机渲染的样式表文件、仅供电视渲染的样式表文件等,具体说明如下表所示:
通过HTML标签的media属性定义样式表的媒体类型,具体方法如下:
- 定义外部样式表文件的媒体类型。
<link href="csss.css" rel="stylesheet" type="text/css" media="handheld" /> - 定义内部样式表文件的媒体类型。
<style type="text/css" media="screen"> ... </style>CSS3在媒体类型的基础上,提出了Media Queries(媒体查询)的概念。媒体查询比CSS2的媒体类型功能更加强大、更加完善。两者的主要区别:媒体查询是一个值或一个范围的值,而媒体类型仅仅是设备的匹配。媒体类型可以帮助用户获取以下数据。 - 浏览器窗口的宽和高。
- 设备的宽和高。
- 设备的手持方向,横向还是竖向。
- 分辨率。
例如,下面这条导入外部样式表的语句:
<link rel="stylesheet" media="screen and (max-width: 600px)" href="small.css" />
在media属性中设置媒体查询的条件(max-width: 600px):当屏幕宽度小于或等于600px时,则调用small.css样式表渲染页面。
1.2、使用@media
CSS3使用@media规则定义媒体查询,简化语法格式如下:
@media [only | not]? <media_type> [and <expression>]* | <expression> [and <expression>]*{/* CSS样式列表 */}
参数简单说明如下:
<media_type>:指定媒体类型,具体说明参考上表所示。<expression>:指定媒体特性。放在一对圆括号中,如(min-width:400px)。- 逻辑运算符,如and(逻辑与)、not(逻辑否)、only(兼容设备)等。
媒体特性包括13种,接收单个的逻辑表达式作为值,或者没有值。大部分特性接收min或max的前缀,用来表示大于等于或者小于等于的逻辑,以此避免使用大于号(>)和小于号(<)字符。
在CSS样式的开头必须定义@media关键字,然后指定媒体类型,再指定媒体特性。媒体特性的格式与样式的格式相似,分为两部分,由冒号分隔,冒号前指定媒体特性,冒号后指定该特性的值。
【示例1】下面语句指定了当设备显示屏幕宽度小于640px时所使用的样式:
@media screen and (max-width: 639px) {/*样式代码*/}
【示例2】可以使用多个媒体查询将同一个样式应用于不同的媒体类型和媒体特性中,媒体查询之间通过逗号分隔,类似于选择器分组:
@media handheld and (min-width:360px),screen and (min-width:480px) {/*样式代码*/}
【示例3】可以在表达式中加上not、only和and等逻辑运算符:
//下面样式代码将被使用在除便携设备之外的其他设备或非彩色便携设备中@media not handheld and (color) {/*样式代码*/}//下面样式代码将被使用在所有非彩色设备中@media all and (not color) {/*样式代码*/}
【示例4】only运算符能够让不支持媒体查询,但是支持媒体类型的设备,将忽略表达式中的样式。例如:
@media only screen and (color) {/*样式代码*/}
对于支持媒体查询的设备来说,能够正确地读取其中的样式,仿佛only运算符不存在一样;对于不支持媒体查询,但支持媒体类型的设备(如IE8)来说,可以识别@media screen关键字,但是由于先读取的是only运算符,而不是screen关键字,将忽略这个样式。
提示:媒体查询也可以用在@import规则和标签中。例如:
@import url(example.css) screen and (width:800px);//下面代码定义了如果页面通过屏幕呈现,且屏幕宽度不超过480px,则加载shetland.css样式表<link rel="stylesheet" type="text/css" media="screen and (max-device-width: 480px)" href="shetland.css" />
1.3、应用@media
【示例1】and运算符用于符号两边规则均满足条件的匹配。
@media screen and (max-width : 600px) {/*匹配宽度小于等于600px的屏幕设备*/}
【示例2】not运算符用于取非,即所有不满足该规则的均匹配。
@media not print {/*匹配除了打印机以外的所有设备*/}
注意:not仅应用于整个媒体查询:
@media not all and (max-width : 500px) {}/*等价于*/@media not (all and (max-width : 500px)) {}/*而不是*/@media (not all) and (max-width : 500px) {}
在逗号媒体查询列表中,not仅会否定它所在的媒体查询,而不影响其他的媒体查询。
如果在复杂的条件中使用not运算符,要显式添加小括号,避免歧义。
【示例3】,(逗号)相当于or运算符,用于两边有一条满足则匹配:
@media screen , (min-width : 800px) {/*匹配屏幕或者宽度大于等于800px的设备*/}
【示例4】在媒体类型中,all是默认值,匹配所有设备:
@media all {/*可以过滤不支持media的浏览器*/}
常用的媒体类型有screen匹配屏幕显示器、print匹配打印输出。
【示例5】使用媒体查询时,必须加括号,一个括号就是一个查询:
@media (max-width : 600px) {/*匹配界面宽度小于等于600px的设备*/}@media (min-width : 400px) {/*匹配界面宽度大于等于400px的设备*/}@media (max-device-width : 800px) {/*匹配设备(不是界面)宽度小于等于800px的设备*/}@media (min-device-width : 600px) {/*匹配设备(不是界面)宽度大于等于600px的设备*/}
提示:在设计手机网页时,应该使用device-width/device-height,因为手机浏览器默认会对页面进行一些缩放,如果按照设备的宽、高进行匹配,会更接近预期的效果。
【示例6】媒体查询允许相互嵌套,这样可以优化代码,避免冗余:
@media not print {/*通用样式*/@media (max-width:600px) {/*此条匹配宽度小于等于600px的非打印机设备 */}@media (min-width:600px) {/*此条匹配宽度大于等于600px的非打印机设备 */}}
【示例7】在设计响应式页面时,用户应该根据实际需要,先确定自适应分辨率的阀值,也就是页面响应的临界点:
@media (min-width: 768px){/* >=768px的设备 */}@media (min-width: 992px){/* >=992px的设备 */}@media (min-width: 1200){/* >=1200px的设备 */}
注意:下面样式顺序是错误的,因为后面的查询范围将覆盖前面的查询范围,导致前面的媒体查询失效。
@media (min-width: 1200){ }@media (min-width: 992px){ }@media (min-width: 768px){ }
因此,当我们使用min-width媒体特性时,应该按从小到大的顺序设计各个阀值。同理如果使用max-width时,就应该按从大到小的顺序设计各个阀值。
@media (max-width: 1199){/* <=1199px的设备 */}@media (max-width: 991px){/* <=991px的设备 */}@media (max-width: 767px){/* <=768px的设备 */}
【示例8】用户可以创建多个样式表,以适应不同媒体类型的宽度范围。当然,更有效率的方法是将多个媒体查询整合在一个样式表文件中,这样可以减少请求的数量:
@media only screen and (min-device-width : 320px) and (max-device-width : 480px) {/*样式列表 */}@media only screen and (min-width : 321px) {/*样式列表 */}@media only screen and (max-width : 320px) {/*样式列表 */}
【示例9】如果从资源的组织和维护的角度考虑,可以选择使用多个样式表的方式实现媒体查询,这样做更高效。
<link rel="stylesheet" media="screen and (max-width: 600px)" href="small.css" /><link rel="stylesheet" media="screen and (min-width: 600px)" href="large.css" /><link rel="stylesheet" media="print" href="print.css" />
【示例10】使用orientation属性可以判断设备屏幕当前是横屏(值为landscape)还是竖屏(值为portrait)。
@media screen and (orientation: landscape) {.iPadLandscape {width: 30%;float: right;}}@media screen and (orientation: portrait) {.iPadPortrait {clear: both;}}
不过,orientation属性只在iPad上有效,对于其他可以转屏的设备(如iPhone),可以使用min-device-width和max-device-width变通实现。
【扩展】媒体查询仅是一种纯CSS方式实现响应式Web设计的方法,也可以使用JavaScript库来实现同样的设计。例如,下载css3-mediaqueries.js(http://code.google.com/p/css3-mediaqueries-js/),然后在页面中调用。对于老式浏览器(如IE6、IE7、IE8)可以考虑使用css3-mediaqueries.js兼容。
<!–[if lt IE 9]><script src=”http://css3-mediaqueries-js.googlecode.com/svn/trunk/css3-mediaqueries.js”></script><![endif]–>
【示例11】演示使用jQuery检测浏览器宽度,并为不同的视口调用不同的样式表。
<script type="text/javascript" src="http://ajax.googleapis.com/ajax/libs/jquery/1.9.1/jquery.min.js"></script><script type="text/javascript">$(document).ready(function(){$(window).bind("resize", resizeWindow);function resizeWindow(e){var newWindowWidth = $(window).width();if(newWindowWidth < 600){$("link[rel=stylesheet]").attr({href : "mobile.css"});}else if(newWindowWidth > 600){$("link[rel=stylesheet]").attr({href : "style.css"});}}});</script>
2、案例实战
2.1、判断显示屏幕宽度
下面示例演示如何正确使用@media规则,判断当前视口宽度位于什么范围。示例代码如下:
<style type="text/css">.wrapper { /* 定义测试条的样式 */padding: 5px 10px; margin: 40px;text-align:center; color:#999;border: solid 1px #999;}.viewing-area span { /* 默认情况下隐藏提示文本信息 */color: #666;display: none;}/* 应用于移动设备,且设备最大宽度为480px */@media screen and (max-device-width: 480px) {.a { background: #ccc;}}/* 显示屏幕宽度小于等于600px */@media screen and (max-width: 600px) {.b {background: red; color:#fff;border: solid 1px #000;}span.lt600 { display: inline-block; }}/* 显示屏幕宽度介于600~900px */@media screen and (min-width: 600px) and (max-width: 900px) {.c {background: red; color:#fff;border: solid 1px #000;}span.bt600-900 { display: inline-block; }}/* 显示屏幕宽度大于等于900px */@media screen and (min-width: 900px) {.d {background: red; color:#fff;border: solid 1px #000;}span.gt900 { display: inline-block; }}</style><div class="wrapper a">设备最大宽度为480px。</div><div class="wrapper b">显示屏幕宽度小于等于600px </div><div class="wrapper c">显示屏幕宽度介于600~900px</div><div class="wrapper d">显示屏幕宽度大于等于900px </div><p class="viewing-area"><strong>当前显示屏幕宽度:</strong><span class="lt600">小于等于600px</span><span class="bt600-900">介于600~900px</span><span class="gt900">大于等于900px</span></p>
示例设计当显示屏幕宽度小于等于600px时,则高亮显示<div class="wrapper b">测试条,并在底部显示提示信息:小于等于600px;当显示屏幕宽度介于600~900px时,则高亮显示<div class="wrapper c">测试条,并在底部显示提示信息:介于600~900px;显示屏幕宽度大于等于900px时,则高亮显示<div class="wrapper d">测试条,并在底部显示提示信息:大于等于900px;当设备宽度小于等于480px时,则高亮显示<div class="wrapper a">测试条。

2.2、设计响应式版式
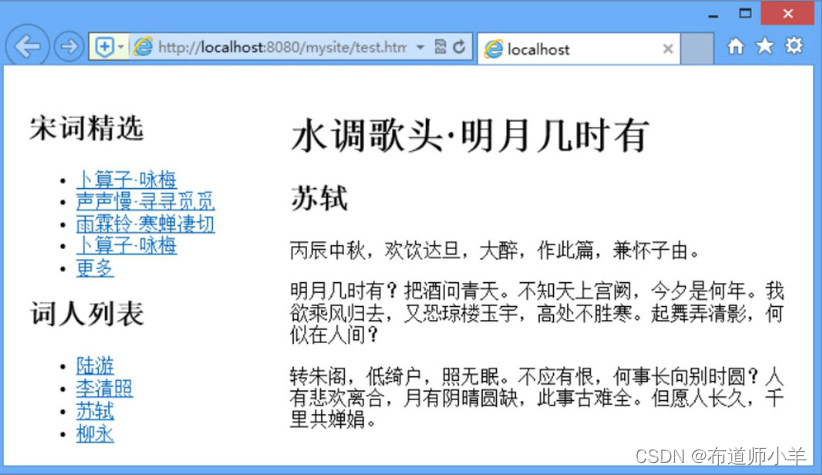
本案例在页面中设计3个栏目。
<div id="main">:主要内容栏目。<div id="sub">:次要内容栏目。<div id="sidebar">:侧边栏栏目。
构建的页面结构如下:
<div id="container"><div id="wrapper"><div id="main"><h1>水调歌头·明月几时有</h1><h2>苏轼</h2><p>……</p></div><div id="sub"><h2>宋词精选</h2><ul><li>……</li></ul></div></div><div id="sidebar"><h2>词人列表</h2><ul><li>……</li></ul></div></div>
设计页面能够自适应屏幕宽度,呈现不同的版式布局。当显示屏幕宽度在999px以上时,让3个栏目并列显示;当显示屏幕宽度在639px以上、1000px以下时,设计两栏目显示;当显示屏幕宽度在640px以下时,让3个栏目堆叠显示。
<style type="text/css">/* 默认样式 *//* 网页宽度固定,并居中显示 */#container { width: 960px; margin: auto;}/*主体宽度 */#wrapper {width: 740px; float: left;}/*设计3栏并列显示*/#main {width: 520px; float: right;}#sub { width: 200px; float: left;}#sidebar { width: 200px; float: right;}/* 窗口宽度在999px以上 */@media screen and (min-width: 1000px) {/* 3栏显示*/#container { width: 1000px; }#wrapper { width: 780px; float: left; }#main {width: 560px; float: right; }#sub { width: 200px; float: left; }#sidebar { width: 200px; float: right; }}/* 窗口宽度在639px以上、1000px以下 */@media screen and (min-width: 640px) and (max-width: 999px) {/* 2栏显示 */#container { width: 640px; }#wrapper { width: 640px; float: none; }.height { line-height: 300px; }#main { width: 420px; float: right; }#sub {width: 200px; float: left; }#sidebar {width: 100%; float: none; }}/* 窗口宽度在640px以下 */@media screen and (max-width: 639px) {/* 1栏显示 */#container { width: 100%; }#wrapper { width: 100%; float: none; }#main {width: 100%; float: none; }#sub { width: 100%; float: none; }#sidebar { width: 100%; float: none; }}</style>
当显示屏幕宽度在999px以上时,3栏并列显示,预览效果如下图: