北京公司公示在哪个网站杭州的网站建设公司
Qt是一个卓越的客户端跨平台开发框架,可以在Windows、Linux、macOS进行客户端开发,无缝切换,一统三端;当然除了桌面端,在移动端的早期,Qt也展现了其多才多艺,在Android和ios也可以使用Qt编写app, 近些年移动端的蓬勃发展,大浪淘沙,Qt已退出移动端开发的舞台,但是在桌面端开发,尤其是跨平台方面,Qt是不二选择。
Qt开发灵活多变,可以选用C++或Python,但要说到企业级桌面端项目,尤其对性能有要求的桌面端项目,C++无疑是首选。由于历史原因,很多第三方库都是使用C/C++编写,这些第三方库也经过了数十年的使用与验证,程序员在选择时不存在顾虑,linux、windows的系统接口则全是C/C++,使用C++可以更好的与第三方库、操作系统进行交互,同时C++的性能也高于其它语言,因此C++无疑是大多数企业桌面端项目的首选。Qt由于其较好的封装,使用简单,有着web的ui效果,同时也可以与web混合开发,或者把CEF集成到Qt, 实现更高效的c++ qt web混合开发效率,因此使用C++ Qt作为桌面端项目技术选型是很好的选择。例如腾讯会议、剪映、亿图MindMaster、优酷(2022年3月之前),斗鱼,AutoCAD等大型桌面端软件都是使用C++ Qt进行开发。
近年来,Qt更是热情推崇QML开发。这给许多开发者带来了疑虑,让很多Qt开发者站在了十字路口,选择QML还是QWidget?是走向PyQt,还是坚守C++ Qt,或是探索QML的新境界?学习QWidget是否过时了,企业里用qml多还是QWidget多;是学习PyQt,还是学习C++ Qt,还是学习qml;学习Qt,操作系统该怎么选,是在linux里学习,还是windows里学习,还是在mac里学习;由于C++开发环境的多样性,学习Qt该用哪个IDE,是使用QtCreator,还是使用VS Code, 还是使用VS2022;为什么Qt环境经常出问题,报错,无法编译,常量换行符,中文乱码,许多人感到困惑和沮丧。
学C++ Qt开发,需要先学习C++, 再学习Qt,然后做项目。很多人觉得C++难学,被一些视频,文章误导,直接被劝退。C++难,但并不是学不会,我当初也很想放弃C++, 但是我坚持下来了。
这些年通过写博客,录教程,在qq群里和大家交流,了解到大家对Qt开发的困惑,经过多年的深入研究以及项目应用,我录制了三套视频教程,构建了一条C++ Qt的学习高速公路,让Qt开发者不在有难写的界面,不再被复杂的界面问题所困扰,当然课程里也有不少黑粉攻击,也有很多粉丝朋友的支持,在课程答疑群里,我也会尽自己所能为学员门解答,让每一个有志于C++ Qt开发的人,都能迅速上手并投入项目实战。本套教程一共3个阶段:
(1)C++零基础入门,
(2)Qt开发入门到高级进阶,
(3)C++ Qt开源项目OBS源码分析与应用。
本套课程由浅入深,详细的介绍了C++入门、Qt入门进阶到企业级项目实战、C++ Qt开源项目学习。相信通过本套教程的3门课程的学习,大家可以很好的掌握C++ Qt开发,课程提供答疑服务。
教程链接:C++ Qt入门进阶与企业级项目实战-CSDN程序员研修院
下面是各个阶段的介绍
阶段一:C++零基础入门与进阶
C++零基础入门课程链接:2023 C++零基础入门视频教程_在线视频教程-CSDN程序员研修院
C++零基础入门课程,一共19个大章节,课件内容大概11万字, 由于C++有一部分知识点和C语言重合,本课程也附带讲解C语言的知识点,学习本课程是同时掌握两门语言,前10章是C和C++的共同部分,如果出现二者的区别会分开讲解。
课程主要内容如下:
C++ Linux开发环境搭建
(1)学习虚拟机安装,Ubuntu Server安装,Ubuntu C++开发组件安装,VS Code Ubuntu C++开发环境搭建。
(2)学习Windows WSL子系统安装与C++开发环境搭建。
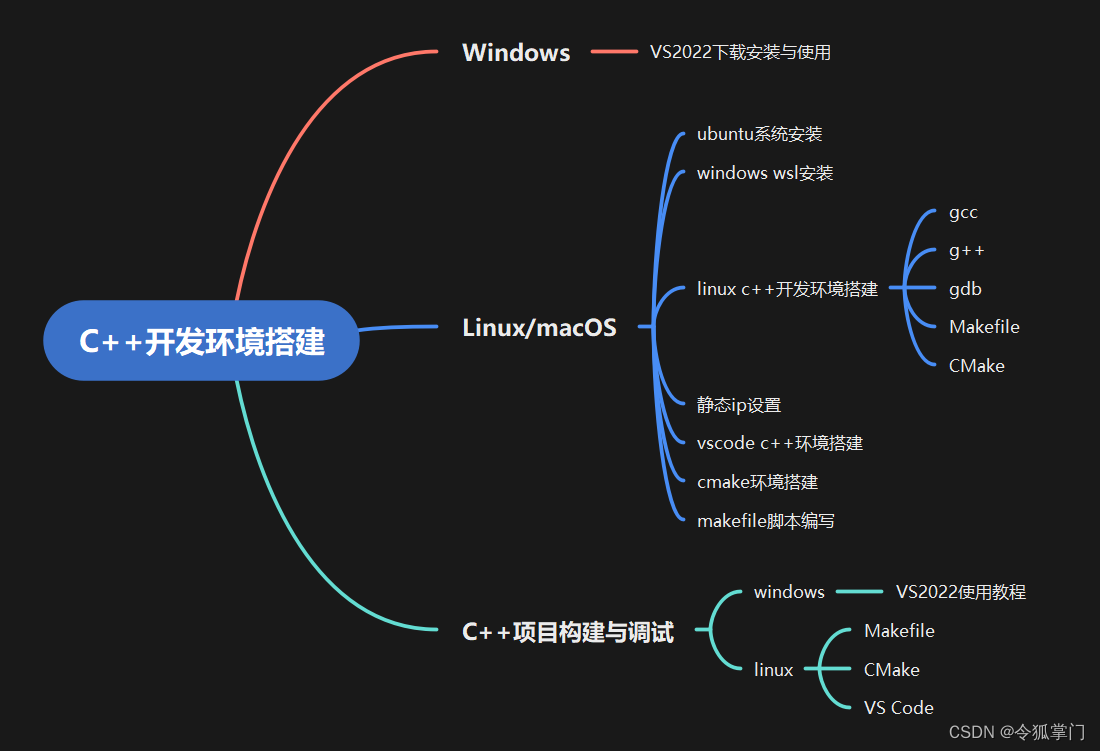
C++ Windows开发环境搭建
学习Win11下VS2022安装与C++项目构建与调试
C/C++基础语法
学习C/C++基础语法,标识符,变量,基本输入输出,运算符,循环控制,数组,指针与引用,字符串等知识点。
Linux VSCode C++调试
学习linux静态ip设置,VS Code连接Ubuntu编写C++项目,学习在VS Code里如何调试C++项目。
VS2022 C++调试
学习使用VS2022创建C++项目,介绍VS2022项目配置,VS2022与VS Code的区别。
Makefile
学习在Linux下如何使用Makefile进行C++多目录多文件项目构建与调试。
CMake
学习使用CMake构建C++项目,学习VS Code CMake进行项目调试。
C/C++内存管理
内存管理是C++程序员的痛点,本课程会详细介绍C内存操作的相关函数,以及C内存池,C++ new与delete, 以及C++智能指针与new , delete之间的联系。
函数
学习函数的函数的声明,函数参数的各种形式,函数指针,变参函数,全局函数等等
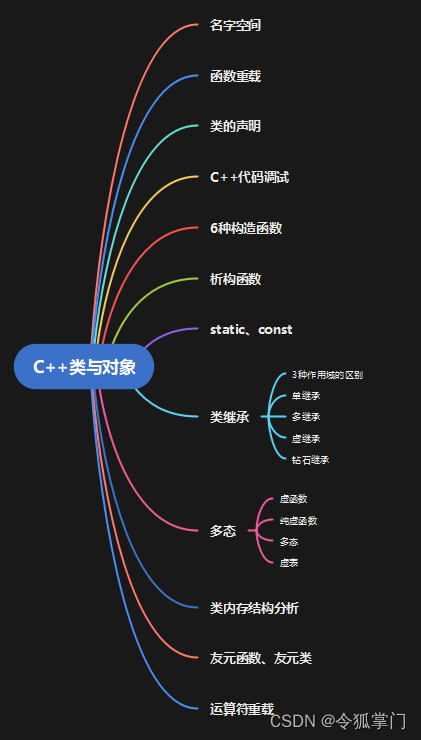
C++类与对象
第11章C++类与对象是本课程的核心,本章会详细介绍C++类的各个知识点,名字空间,函数重载,类的声明,6中构造函数,析构函数,static, const关键字在类以及类对象的用法,类继承,多继承,虚继承,钻石继承,虚函数,纯虚函数,多态,类内存结构分析,友元函数,友元类,运算符重载等知识点。
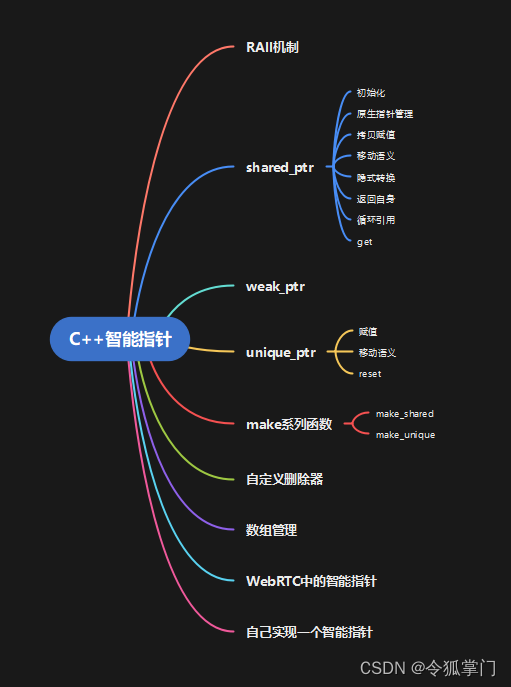
C++智能指针
智能指针是本课程第二个重点章节,本章节会详细介绍RAII机制,shared_ptr, weak_ptr, unique_ptr的用法,智能指针make系列函数的用法,自定义删除器,智能指针管理数组,以及开源项目WebRTC里智能指针的用法。
C++标准库学习
学习玩类与对象,模板元编程、智能指针后,再来学习C++标准库,标准库知识点较多,在课程的第14章会详细介绍标准库里各种容器的用法。
C++职业发展介绍
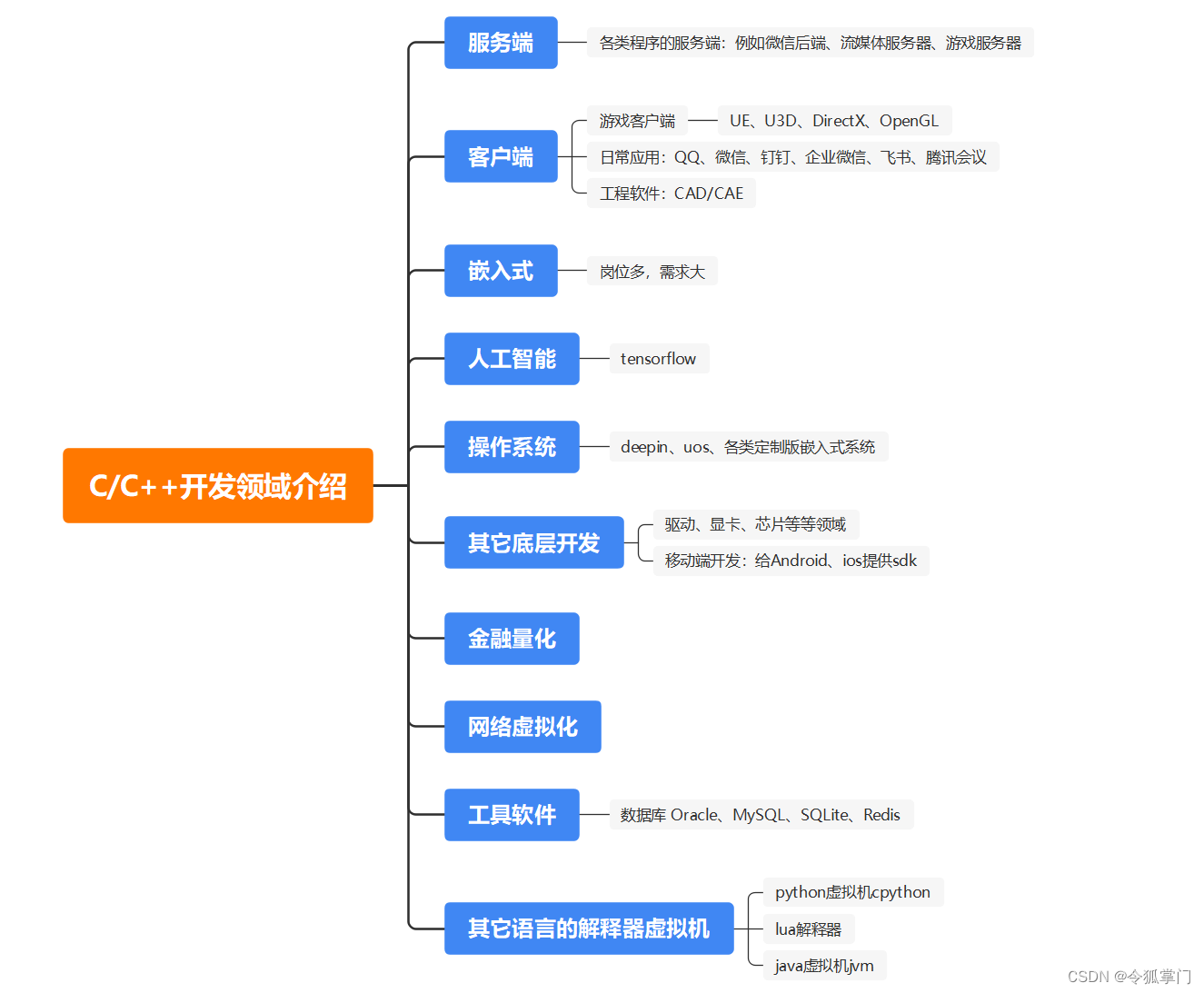
阶段二:Qt入门进阶与企业级高级开发
课程链接:Qt高级开发视频教程_在线视频教程-CSDN程序员研修院
课程主要内容如下:
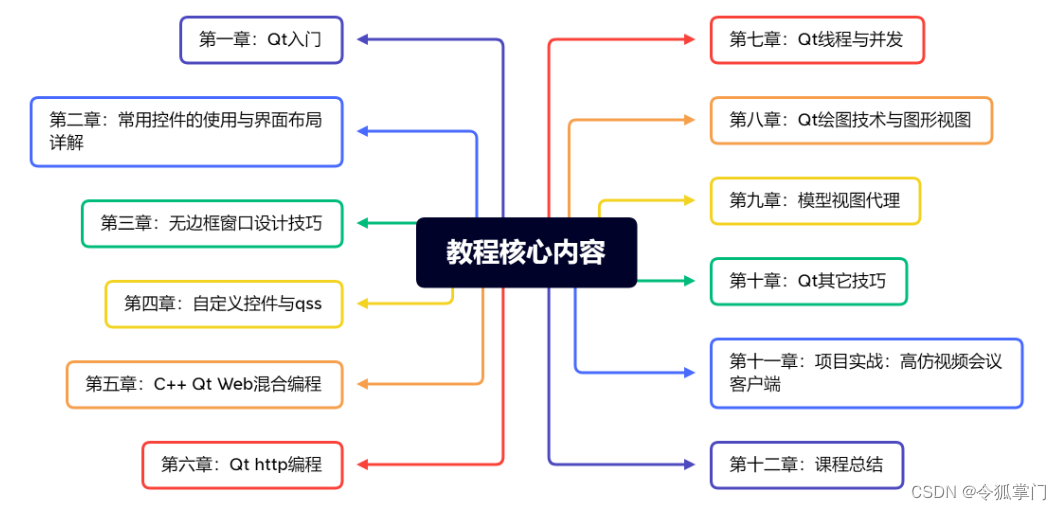
课程每章核心知识点介绍如下:
第一章:介绍Qt环境搭建、QtCreator / VS2019的基本使用方法,Qt整体架构、Qt信号机制,Qt内存管理等知识。
第二章:了解到很多学员对于Qt界面布局很不熟悉,将会详细介绍Qt设计器布局,以及如何C++代码手写布局,从常见的企业级项目入手,带领大家学会各种布局的实现,例如WPS、腾讯会议、优酷、迅雷等界面的实现;界面布局会了,这是企业项目开发的第一步,还有更重要的无边框窗口,如何设计一个合理的无边框窗口很重要,
第三/四章:详细介绍如何实现一个无边框窗口,如何自定义标题栏,如何实现拖拽拉伸;第四章将会介绍如何自定义非标控件,优化Qt界面。
第五章:介绍Qt web混合编程,一个商用项目,必然会涉及到web交互,这也是很多Qt开发者的弱项,这一章讲详细介绍C++ Qt web混合开发。
第六章:既然是做企业级项目,必然需要和后台交互,http编程也是必要的,将详细介绍http编程,用户注册,登录,后台接口请求等知识;通过第五、六章的学习,将会是你的Qt开发技术更上一层楼。
第七章:介绍Qt并发编程,耗时任务处理,进程调用等知识。
第八、九章:讲解 Qt 比较重要的知识,图形视图结构,以及MVD模式;通过这两章的学习,大家会对图形视图有更好的了解。
第十章:本章是独立章节,主要介绍Qt中一些特殊技巧,项目编译,dpi适配、多语言等知识。
第十一章:是我们的企业级项目实战:实现一个视频会议客户端,本项目可以进行多人视频通话,直播,桌面分享等功能,本项目我会从零开始,进行项目搭建,功能调试,bug fixed, 带领大家做一个企业级项目。
希望通过本课程的学习,大家的C++ Qt开发技术能有质的飞越,能找到自己心仪的工作。
下面是本课程一些项目的截图:
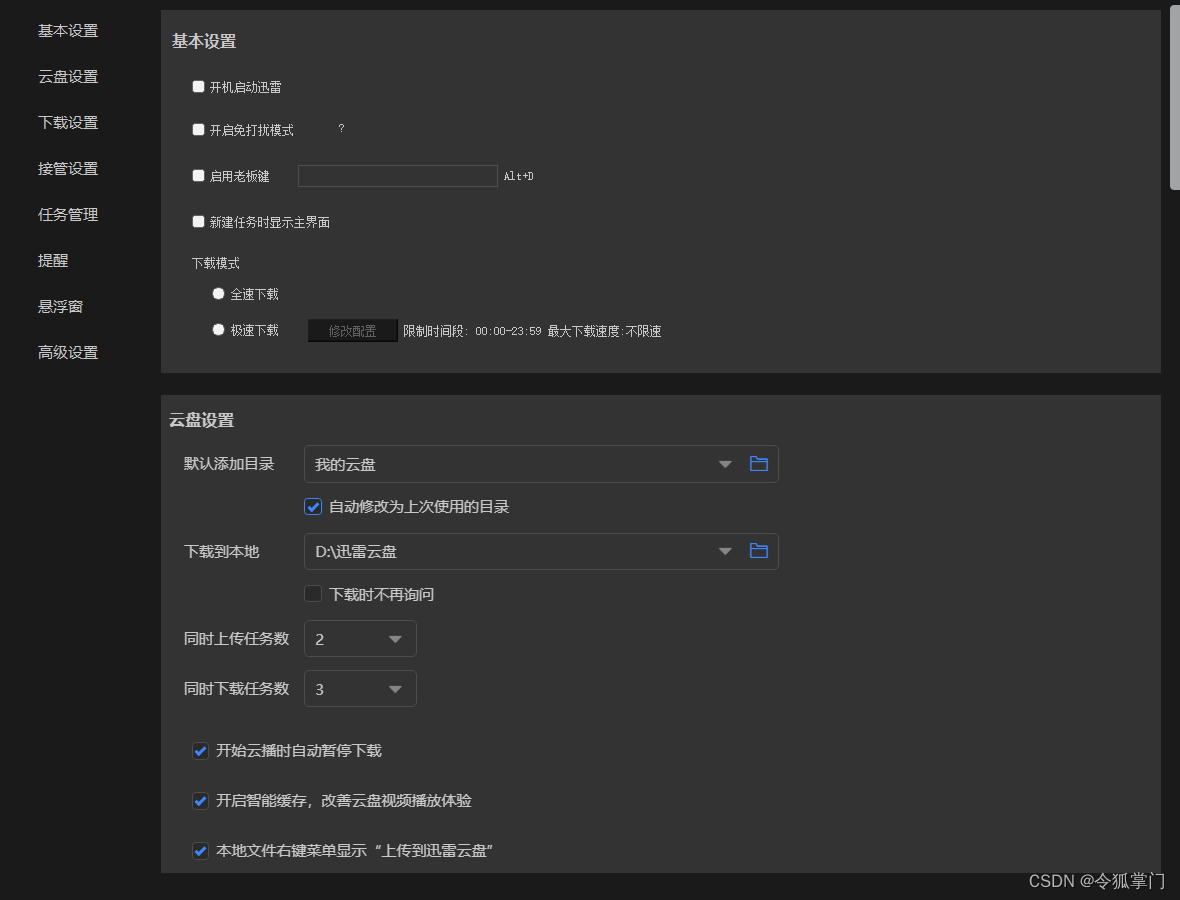
1 可以滑动的设置界面(高仿迅雷设置界面)
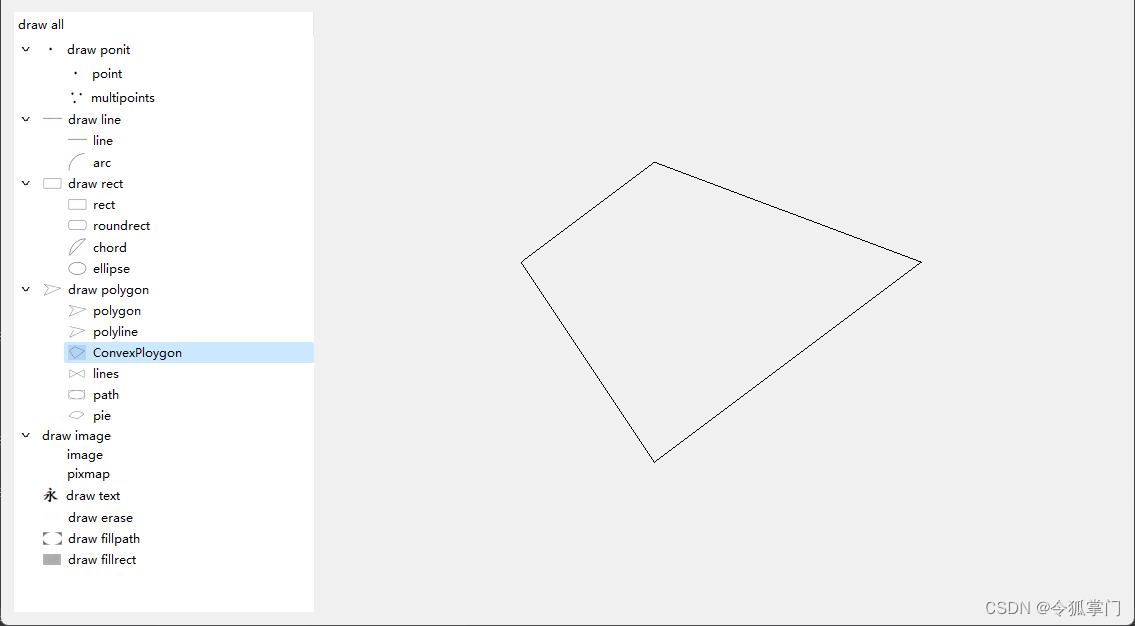
2 所有图形的绘制
3 视频播放器
4 视频会议
登陆页面
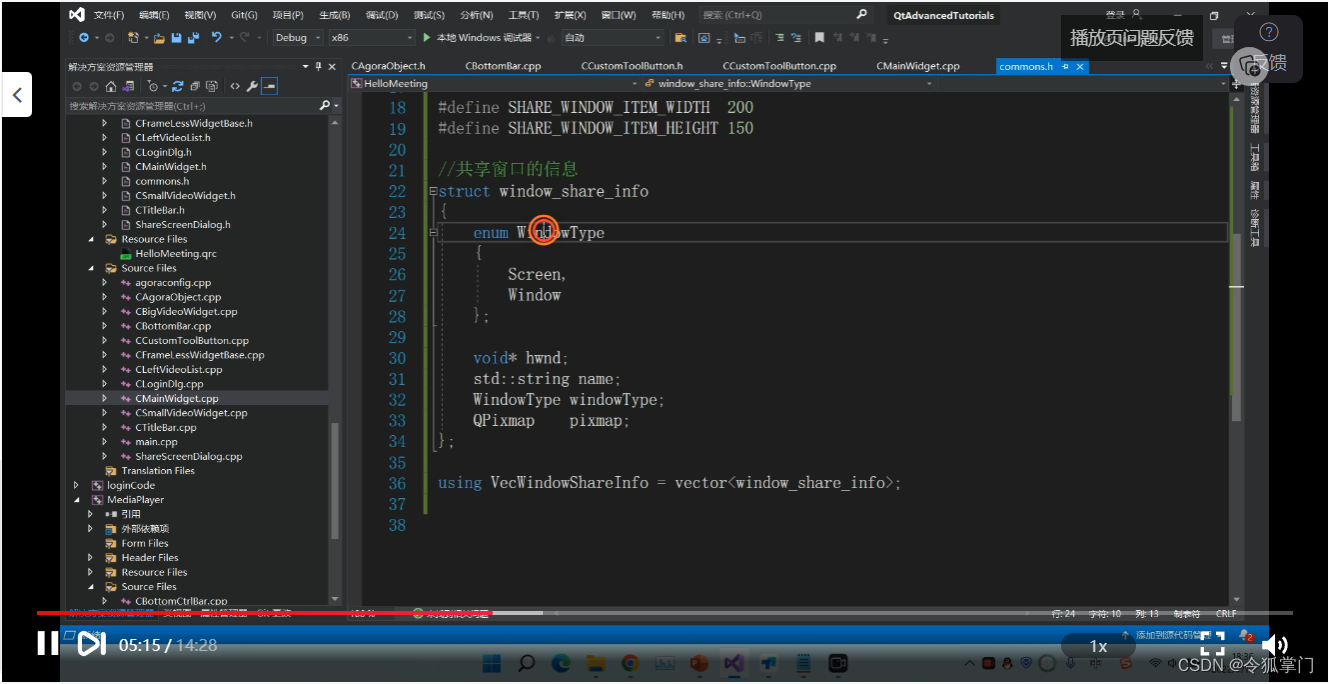
桌面共享代码
项目运行效果
阶段三:C++ Qt开源项目学习源码分析与应用
C++ OBS课程链接:C++ Qt OBS源码屏幕录制软件开发视频教程_在线视频教程-CSDN程序员研修院
本课程主要讲解OBS源码的编译,OBS功能实现,初始化,显示器录制,窗口的实现录制,以及录制模块源码详细分析,最后基于OBS源码开发了一个录制软件,界面如下:
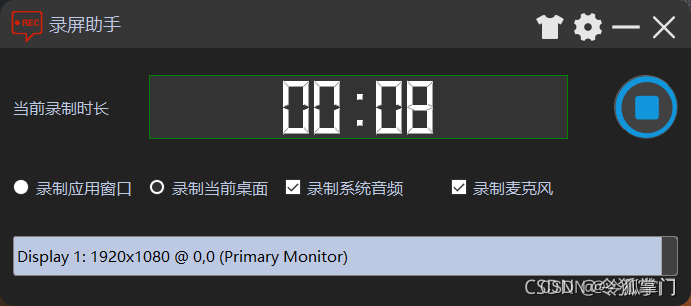
主要有如下功能
(1)实现桌面,显示器采集、录制
(2)指定应用程序窗口进行录制
(3)可以选择系统声音,麦克风进行录制
(4)稳定fps 60,高清原画,鼠标不闪,、音视频同步,无卡顿,无延时
(5)可以指定帧率录制,5-60 fps都可以
(6)显示了系统托盘,录制时可以最小化到系统托盘
OBS课程大纲
OBS源码分析
初始化流程
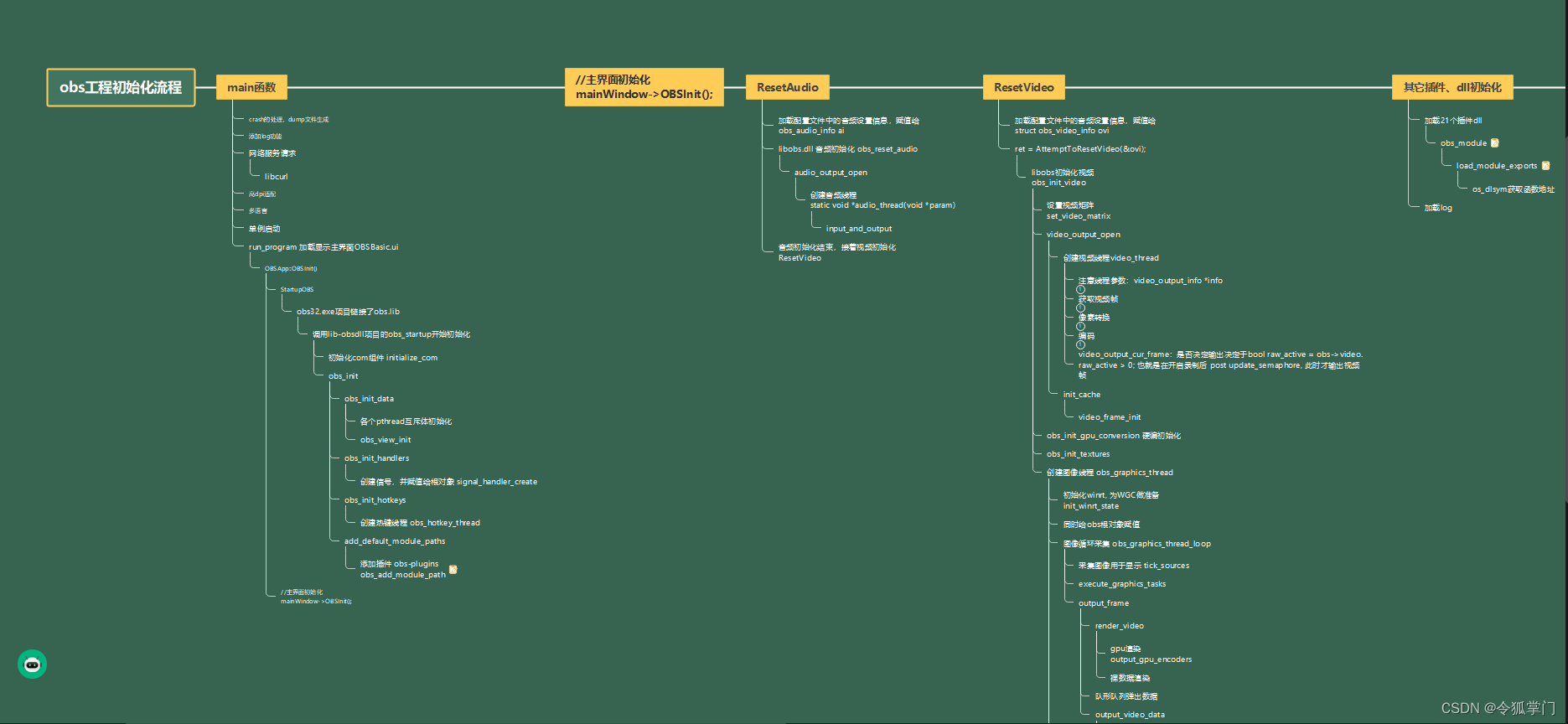
OBS录制流程分析
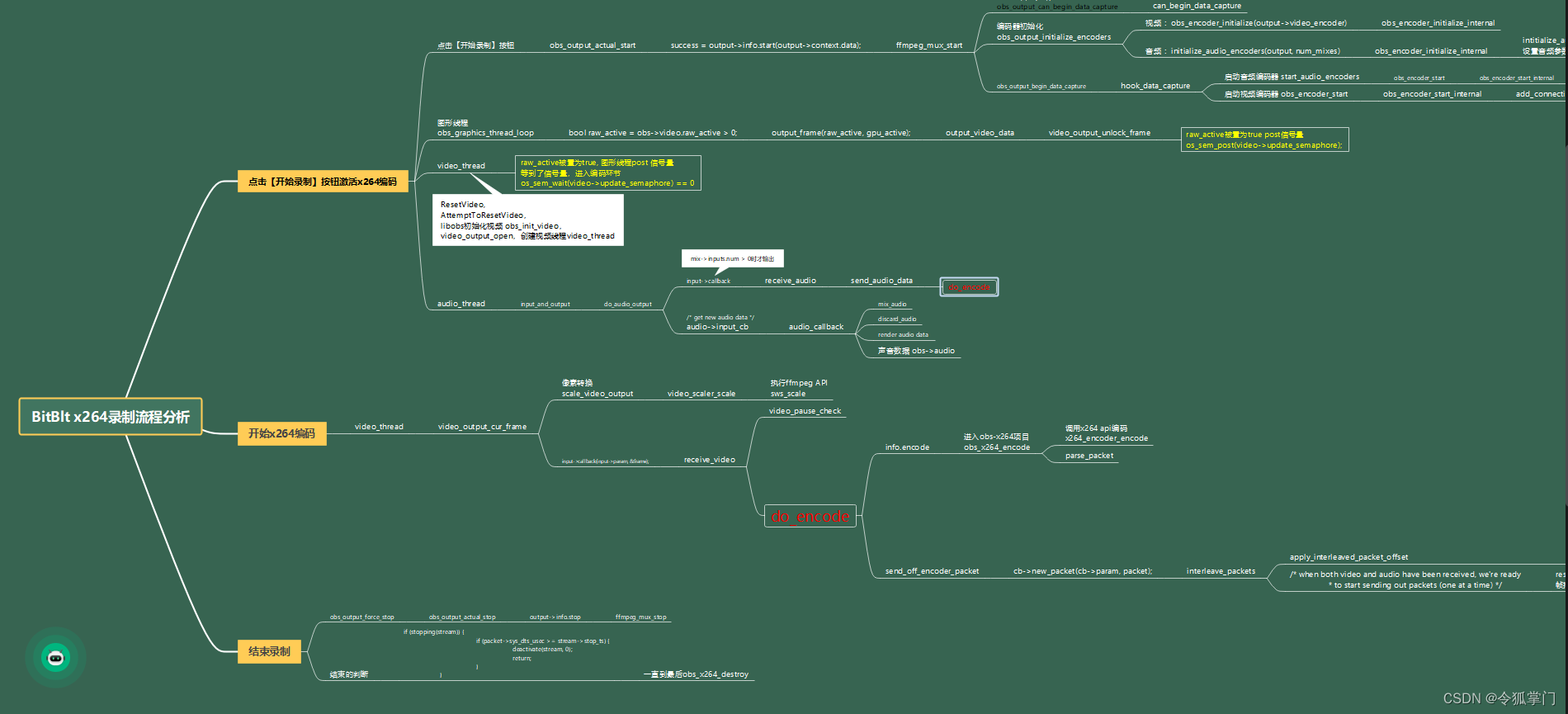
以上3个课程均提供全部源码,提供答疑服务。