番禺做网站报价网站推广软文几个绝招
本文正在参加「金石计划」
Prefetch 是一个谎言
我们知道,现在的应用程序已经发展到可以拆分为多个 JavaScript包了,为了获得更好的用户体验,这些 bundle 包通常需要预获取,即 prefetch! 但是现在的prefetch 效果有多糟糕我想你也知道。
例如,为了让应用程序拆解成多个包,在你的代码的某些地方,你会进行动态导入,比如 import('./some-dependency.js')。但是作为开发人员,你或许也会在代码片段中插入额外的动态导入。下面这段代码中,假设你将代码放在惰性加载块后面的 Buy 按钮后面,看起来像这样:
export default () => {return (<div><button onClick={async () => {// 惰性加载点击“购买”按钮背后的逻辑。(await import('./buy.js')).default();}}>Buy</button></div>);
};
但是这样做,现在你就会有一个新的问题要解决!当用户单击 Buy 按钮时,浏览器会惰性加载 buy.js 包。根据 bundle 的大小和网络的速度,这可能会引入一个显著的、明显的延迟。那我们能做些什么来改善呢?
Prefetch
幸运的是,浏览器自带 Prefetch 支持!所以你会把这样的东西放到头部部分。这个时候,你可能认为你已经解决上面提到问题。
<head><link rel="prefetch" href="buy.js"/><!-- 或选择一个可替代的策略<link rel="preload" href="buy.js"/><link rel="modulepreload" href="buy.js"/>-->
</head>
但是这段代码真的会如你所愿吗? 你也不太确定,因此接着,你在 Chrome 中测试它,发现一切都能正常工作。
但是很快,你就会得到反馈,在许多情况下,用户必须等待 Buy 按钮执行其操作。这种额外的等待正是损害用户体验的底线。那 prefetch 为什么不能如你所愿呢? 原因主要由几点:
Modulepreload不能在大多数浏览器中使用。- Firefox 有
network.dns.disablePrefetchFromHTTPS选项,默认设置为true。默认情况下,Firefox 不会在HTTPS上 prefetch 任何内容。考虑到现在大多数东西都是 HTTPS,这有效地禁用了Firefox上的预取。 - 一些移动浏览器忽略 prefetch,因为移动浏览器认为这是在移动网络上,并试图节省带宽。
在闲置的时候加载
因此,大多数浏览器只在 network 空闲时才处理 prefetch。这是有意义的,但是为了让应用程序具有交互性,需要确保在出现次要事物(如高分辨率图像)之前出现交互性。如果等到页面上的所有东西都加载后才开始获取JavaScript,通常为时已晚。
你可以想象一个网站向你展示照片的时候。如果照片很大,需要下载一段时间。但你想在所有照片下载之前就开始与网站互动。但在所有图像都被解析之后再来获取 JavaScript 可能不是你想要的,因为这样会耗费你的耐心。
这个问题实际上说明了缺乏对浏览器中“何时”解析 Prefetch 的控制。
重复加载
prefetch 本应改善交互性,但在某些情况下,它可能会恶化交互性。
例如下面这段代码:
// 1. prefetch 开始
<link rel="prefetch" href="buy.js"/>// 2. 用户交互需要执行code,但是 prefetch 没有生效,于是重新 prefetch
<button onClick={async () => {// 惰性加载点击“购买”按钮背后的逻辑。(await import('./buy.js')).default();
}}>Buy</button>
想象一下如果你的连接速度很慢的时候,开始 Prefetch 并开始下载JavaScript。在JavaScript完全下载之前,用户与应用程序进行交互。现在,import('./buy.js') 被执行,但是 buy.js 不在缓存中。正在运行的 buy.js 请求尚未完成。但是由于请求是不完整的,浏览器不知道缓存头是什么,所以它不知道重用请求是否安全。所以浏览器做了安全的事情,发出另一个 buy.js 资源请求。现在,对同一资源的两个请求正在运行。
更糟糕的是,原始资源被解析,buy.js 被插入到浏览器缓存中,但是资源的解析并没有解除用户交互的阻塞。相反,UI 必须等待第二个 buy.js 返回,然后才能解除阻塞。
因此,prefetch 在某些情况下,可能导致多次请求相同的资源。
来自 Console 的警告
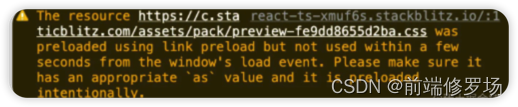
最后,如果某些浏览器检测到给定的预取资源在 x 秒内未被使用,则会发出控制台警告。因为浏览器会认为,你没有使用到它,就不应该预取它。
该怎么做
我觉得真正的 prefetch 是一种提示,告诉浏览器你将需要一些东西,因此浏览器应该在下载时有一个良好的开端,但我们想要的是用 用户可能需要的交互代码预填充缓存。
理想情况下,我们希望控制缓存,以便:
- 控制何时填充缓存。
- 理解 chunk 的依赖关系图,这样我们也可以 prefetch 合成的 bundle。
- 控制请求,以便在请求尚未在 bundle 中时可以解除请求。
简单而言,我们希望从一个被动的执行预取转变为一个主动控制预取。
事实证明,service worker 能做到。Service worker 可以拦截请求并控制缓存中的内容。使用 service worker,我们可以对流程进行正确的控制,还可以了解 chunk 依赖关系图,并可以加载相关代码。
但是创建这样一个service worker并不容易,所以大多数开发人员都不这么做。
结论
你或许经常看到是“专家”给出的常见的性能优化建议中包含了 prefetch,以确保惰性加载的块不会对用户交互造成延迟。但事实证明,现实从来没有这么简单,使用 prefetch 在实践中并不像你所希望的那样有效。
相反,我们建议使用 service worker 来完全控制 prefetch 过程。这个结果对我们来说非常有用,因为它允许我们消除由于延迟加载代码而导致的交互延迟。