做电子商务平台网站需要多少钱五分钟wordpress
Git是什么?
Git是目前世界上最先进的分布式版本控制系统(没有之一)
什么是版本控制系统?
程序员开发过程中,对于每次开发对各种文件的修改、增加、删除,达到预期阶段的一个快照就叫做一个版本。
如果有一个系统,能够让我们知道每个版本做了哪些操作、什么时候做的、谁做的,并且能够任意的在各个版本中穿梭、合并等等,这就是版本控制系统!
如下图所示:

为什么要引入版本控制?
这就不得不提及linux的创始人linus了,1991年开源了linux后,2002年之前,所有的全世界的linux开源参与者,都是通过diff的形式,将源代码发给linus,由他本人手动方式合并!
但是随着Linux系统已经发展了十年了,代码库之大让Linus很难继续通过手工方式管理了,社区的弟兄们也对这种方式表达了强烈不满,于是Linus选择了一个商业的版本控制系统BitKeeper,BitKeeper的东家BitMover公司出于人道主义精神,授权Linux社区免费使用这个版本控制系统!
安定团结的大好局面在2005年就被打破了,原因是Linux社区牛人聚集,不免沾染了一些梁山好汉的江湖习气。开发Samba的Andrew试图破解BitKeeper的协议(这么干的其实也不只他一个),被BitMover公司发现了(监控工作做得不错!),于是BitMover公司怒了,要收回Linux社区的免费使用权。
Linus可以向BitMover公司道个歉,保证以后严格管教弟兄们,嗯,这是不可能的。实际情况是这样的:
Linus花了两周时间自己用C写了一个分布式版本控制系统,这就是Git!一个月之内,Linux系统的源码已经由Git管理了!牛是怎么定义的呢?大家可以体会一下。
如何理解集中式和分布式?
集中式版本管理:
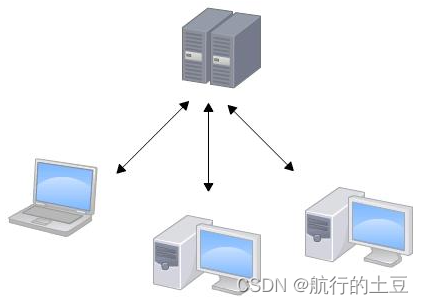
版本库是集中存放在中央服务器的,而干活的时候,用的都是自己的电脑,所以要先从中央服务器取得最新的版本,然后开始干活,干完活了,再把自己的活推送给中央服务器
缺点: 必须联网才能工作,如果在局域网内还好,带宽够大,速度够快,可如果在互联网上,遇到网速慢的话,可能提交一个10M的文件就需要5分钟,这还不得把人给憋死啊。
分布式版本管理:
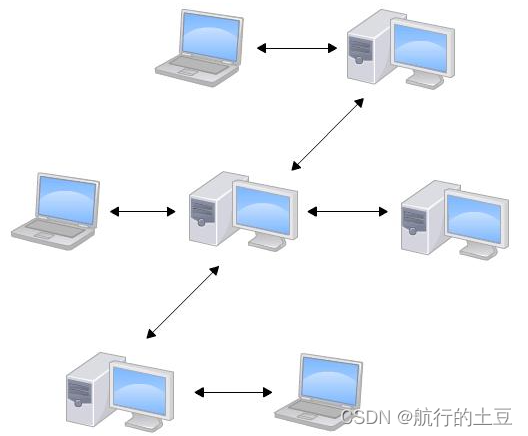
分布式版本控制系统根本没有“中央服务器”,每个人的电脑上都是一个完整的版本库,这样,你工作的时候,就不需要联网。
因为版本库就在你自己的电脑上。既然每个人电脑上都有一个完整的版本库,那多个人如何协作呢?比方说你在自己电脑上改了文件A,你的同事也在他的电脑上改了文件A,这时,你们俩之间只需把各自的修改推送给对方,就可以互相看到对方的修改了。
在实际使用分布式版本控制系统的时候,其实很少在两人之间的电脑上推送版本库的修改,因为可能你们俩不在一个局域网内,两台电脑互相访问不了,也可能今天你的同事病了,他的电脑压根没有开机。
因此,分布式版本控制系统通常也有一台充当“中央服务器”的电脑,但这个服务器的作用仅仅是用来方便“交换”大家的修改,没有它大家也一样干活,只是交换修改不方便而。
Git的安装
这里只介绍Windows的安装,因为安装都是傻瓜式的一直下一步安装!
上Git官网:https://git-scm.com/downloads下载
大家各自选择自己的系统,大同小异:
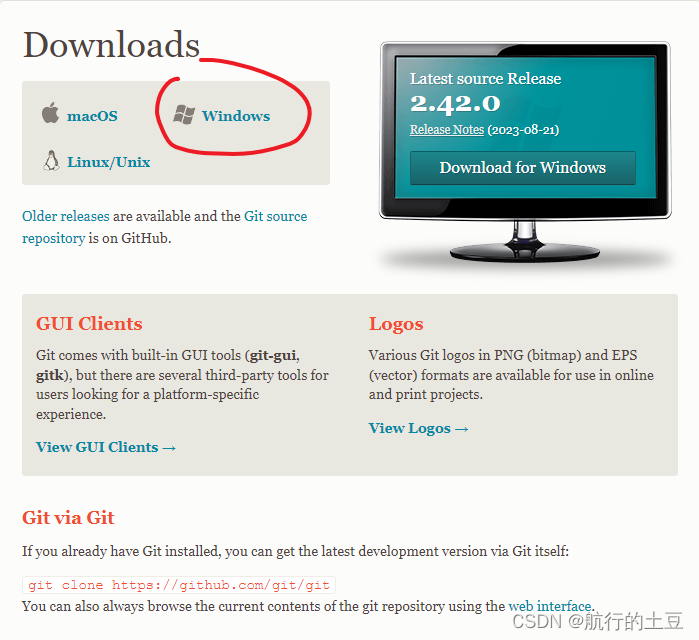
这里有个推荐选项,直接点就好,我电脑是Windows 64 bit的
下载下来,一直下一步就好!(注意安装路径不要带中文字符) 这里不过多介绍!
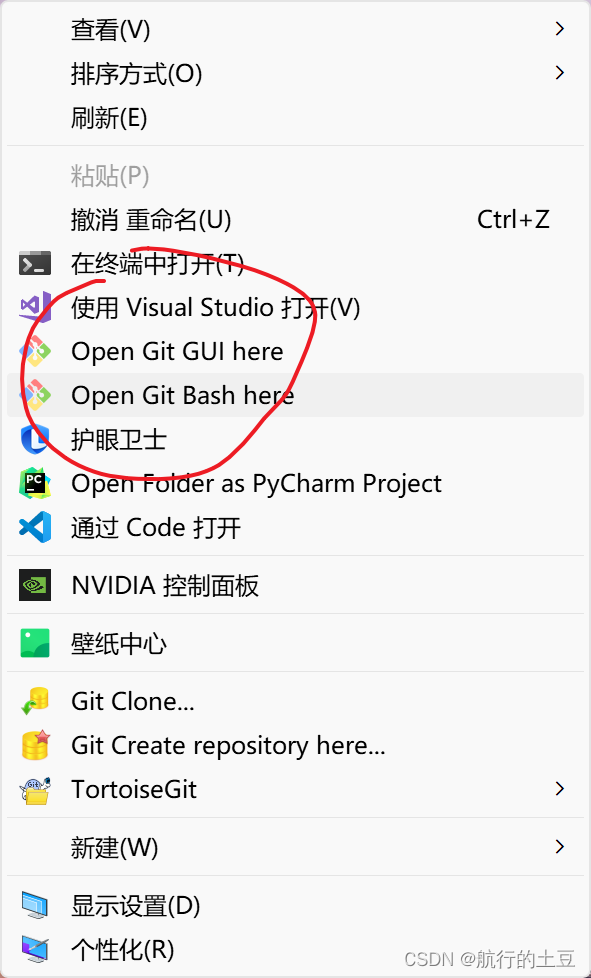
安装完成之后,鼠标右键出现以下红圈图标就表示成功了!