界面十分好看的网站网站设计论文总结与展望
文章目录
- 前言
- 智能硬件的定义与应用
- 智能硬件产品开发流程
- 智能硬件开发所涉及的技术体系概述
- 关于主板选型
- 主板CPU芯片的选择
- 关于串口通信
- 总结
前言
针对我过往工作经历,曾在一家智能科技任职Android开发工程师,简单介绍下关于任职期间接触和开发过的一些项目经历,智能多与物联网(LOT)进行联系,从对Android智能硬件一无所知到现在算是略有小成,期间踩了很多坑,也接触到了许多非Android方面的知识,现用文章的方式将之记录下来,与大家分享。
智能硬件的定义与应用
提到智能硬件其实属于物联网(LOT)的范畴,关于智能硬件的定义,以我理解的角度来看,首先这是一个不同于移动手机的硬件,它本质还是一个可触碰的实质物体;其次关于智能,只要是基于Android系统开发的硬件就可称之为智能,因为智能硬件最关键的特性就是与外部连接通信,也称之为物联网,而Android系统自带优秀的外部连接通信体系。
我们最常听到与见到的智能硬件有手环、智能音箱、智能家居这些比较成熟的消费级商品,这些智能硬件大部分都是没有界面的,与我从事的领域有所不同。没有界面的智能硬件大部分都不是Andriod系统,而有触屏界面的智能硬件我敢说80%以上都是Android系统,因为Android的交互体系绝对是最好的。
市面上成熟的Android智能硬件有:手持POS机、自动售货机、政务自助机、人脸识别门禁、收银机、汽车多媒体、电子班牌、快递柜、影院取票机、广告视频机等等。
智能硬件产品开发流程
导入需求,分析确定需求细节,讨论方案的技术可行性。
确定项目负责人、产品经理、硬件工程师、软件工程师、结构工程师、UI设计师。
由需求确定使用哪些外设,对外设进行选型,需充分考虑性能、质量、结构设计、价格、供应商支持度等各方面的因素。
优先确认使用什么Android主板,确认主板与外设选型后告知结构工程师进行结构外形设计。
硬件工程师负责外接设备的控制板开发并提供接入协议,硬件工程师还须将外设接入Android主板的线材适配好。
UI设计师提供界面给软件工程师(Android),开始进入进行软件开发阶段。
产品样品建模制作出外壳,打磨、喷漆后进行所有元件的组装。
样品烧入程序,开始交予测试。
程序bug修改,稳定性测试。
所有测试通过后,撰写用户文档与操作手册。
一款智能硬件样品全部制作完毕。
智能硬件开发所涉及的技术体系概述
Android UI
列表(RecycleView)
弹窗(Dialog)
动画(Animation)
文字与按钮(TextView)
手势(Gesture)
外部通信
串口通信(UART)
以太网
Wifi、热点
4G
蓝牙
USB
NFC
I2C
GPIO
存储
TF卡
U盘
FTP
Linux系统
脚本
点亮屏幕
固件升级
NDK
音视频播放
设备通讯协议加密
接入已有的C库
语音识别
人脸识别
外接设备
二维码
摄像头
红外感应器
喇叭、麦克风
触摸屏
LCD液晶屏
打印机
NFC模块
IC类读卡器
关于主板选型
Android主板的选型一定要放在首位,因为这是整个产品的控制中心,核心元件,如果不能自己定制主板,那就只能依赖于供应商提供方案。现行市面上非常多做安卓工业主板的,不愁找不到主板,但想要很特殊的定制可能会比较麻烦,除非你的量很大,否则只能用人家的标准板。依赖供应商还有一个特别麻烦的事情,就是系统功能定制的沟通,这是一个特别漫长而痛苦的过程。
结合多个项目的经验,总结出智能硬件在安卓系统中所基本必要的功能。
序号 功能 说明
1 开机自启 智能硬件一般只运行一个应用,且开机就要自动打开
2 保证应用永远在前台运行 让用户永远不会看到除了应用之外的其它安卓界面
3 有接口设置系统时间 有些局域网场景无法连接外网,需要同步局域网服务器时间
4 定时开关机(带RTC电池) 为了让系统更好运行,可能需要每隔几天重启一次
5 静默安装应用,完成后直接拉起应用 更新安装应用过程必须是无感的
6 系统固件更新接口 将新的系统固件放入系统后能用有方法更新
7 支持U盘、TF卡且有路径检测 对于非联网管理的产品必须要能检测到外部存储插入
8 设置静态以太网IP接口 对于某些依赖于IP地址进行管理的产品必须要能设置IP
9 开启/关闭背光电源接口 有些场景可能要求节能环保,关背光很必要
10 读写IO口接口 IO口是控制外设开关的关键功能
11 设置屏幕显示方向 横竖屏根据项目会有不同要求
主板CPU芯片的选择
CPU芯片是一块主板最核心的元件,对于智能硬件而言CPU价格是不能太高的,不然会导致产品成本过高竞争力下降,但CPU性能又不能太差以让产品毫无竞争力可言。从我观察的情况来看,现在市面上的智能硬件基本是三家芯片厂商占据了绝大部分市场,它们分别是:
瑞芯微 Rockchip,简称RK
全志 AllWinner
飞思卡尔 FreeScale
瑞芯微是我接触比较多的,在百度搜安卓主板出来的广告厂商基本都是采用瑞芯微方案的,总体来说瑞芯微方案是最成熟的。
全志的安卓主板给我的感觉就是很便宜但系统都是4.2或4.4,说实话有点落后时代,不是5.0系统以上的主板我都不想碰,界面太丑系统还有点卡。
最后关于飞思卡尔,这是一个国外厂商,我手上还没接触过这个芯片的板子,很少见搭载这个芯片的安卓主板,也许在某些特定应用场景才会考虑这个芯片吧。
下面重点介绍下瑞芯微(下面简称RK芯片)系列4款常见的芯片。
芯片 定位 特性
RK3188 低端 四核Cortex-A9(32位),频率最高1.6GHz,四核Mali-400MP4 GPU,支持OpenGL ES1.1/2.0,1080P视频编解码 (H.264)
RK3288 中端 四核Cortex-A17(32位),主频最高达1.8GHz,Mali-T764 GPU,支持OpenGL ES 1.1/2.0/3.1, OpenCL, DirectX9.3,1080P视频编解码 (H.264/265)
RK3368 中低端 八核64位Cortex-A53,主频最高达1.5GHz,PowerVR G6110 GPU,支持 OpenGL ES 1.1/2.0/3.1,OpenCL,DirectX9.3,1080P视频编解码 (H.264/265)
RK3399 高端 双Cortex-A72+四Cortex-A53大小核CPU结构,主频最高达1.8GHz,Mali-T864 GPU,支持OpenGL ES1.1/2.0/3.0/3.1,OpenVG1.1,OpenCL,DX11,1080P视频编解码
目前RK3288工业主板的价格大概在350~500 之间,RK3399价格在500~700之间,RK3188比3288便宜,RK3368介于3288与3399之间。
对于绝大多数应用场景而言,RK3288绝对能满足需求,价格也比较适中,系统一般是Android5.1不用进行运行时权限适配。RK3399主要用于对于运算能力要求比较高的场景,比如人脸识别,3399还有一大优势就是板子面积相对而言比较小。我目前基本都是采用3288进行开发的,对于智能硬件而言成本还是首要考虑因素,毕竟制造业利润低,苦笑~


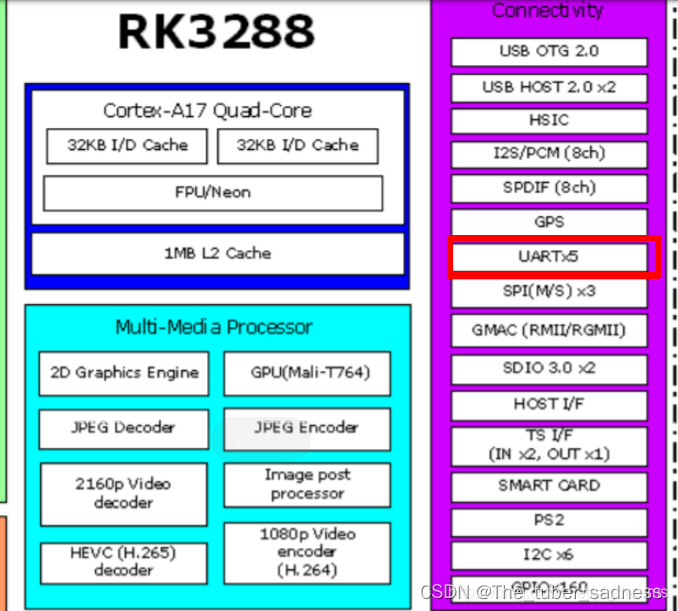
关于串口通信
串口通信是Android智能硬件开发所必须具备的能力,市面上类型众多的外设基本都是通过串口进行数据传输的,所以说不会串口通信根本就做不了智能硬件开发。
首先来看一张RK3288的架构图,在ConnectActivity那一个模块可以发现UART*5的字样,这就表示3288有5个串口可用,其中串口2一般是调试口不开放使用。
总结
以上可以对从事android开发工程师来说大致了解做智能硬件需要了解的一些知识点,和对基础一年电路板的选型尤其是cpu上,真实android软件工程师来说主要还是在底层基础上进行相应有UI效果的开发和编程处理。