如何做正规的采集网站二手优品哪个网站做
蜜獾优化算法(Honey Badger Algorithm,HBA)是期刊“MATHEMATICS AND COMPUTERS IN SIMULATION”(IF 3.6)的2022年智能优化算法

01.引言
蜜獾优化算法(Honey Badger Algorithm,HBA)受蜜獾智能觅食行为的启发,从数学上发展出一种求解优化问题的高效搜索策略。将蜜獾的动态搜索行为分为挖掘和寻蜜两种方法,并将其描述为HBA的探索和开发阶段。此外,通过控制随机化技术,HBA即使在搜索过程结束时也能保持充足的种群多样性。
02.优化算法的流程
蜜獾是一种黑色和白色毛茸茸的哺乳动物,经常在非洲、西南亚和印度次大陆的半沙漠和热带雨林中发现,以其无畏的本性而闻名。这种狗(体长60至77厘米,体重7至13公斤)是无所畏惧的觅食者,捕食60种不同的物种,包括危险的蛇。它是一种聪明的动物,会使用工具,而且它喜欢蜂蜜。它喜欢独自呆在自己挖的洞里,和其他獾相遇只是为了交配。已知的蜜獾有12个亚种。蜜獾没有特定的繁殖季节,因为全年都有幼崽出生。由于它们勇敢的天性,当它们无法逃脱时,它们会毫不犹豫地攻击更大的捕食者(见图1a)。这种动物也可以很容易地爬上树,如图1b所示,以达到鸟巢和蜂巢的食物。蜜獾用嗅觉老鼠的技巧,通过缓慢地连续行走来定位猎物。它开始通过挖掘和最终捕获猎物来确定猎物的大致位置。在一天内,它可以在半径40公里或更大的范围内挖多达50个洞。蜜獾喜欢蜂蜜,但它不善于定位蜂箱。另一方面,导蜜鸟(一种鸟)可以找到蜂巢,但不能得到蜂蜜。这些现象导致了两者之间的关系,鸟将獾带到蜂巢,并用长爪帮助它打开蜂巢,然后两者都享受团队合作的回报。HBA (Honey Badger Algorithm)是一种模仿蜜獾觅食行为的算法。为了寻找食物来源,蜜獾要么闻,要么挖,要么跟着导蜜鸟。我们称第一种情况为挖掘模式,第二种情况为蜂蜜模式。在先验模式中,它利用嗅觉能力来估计猎物的位置;当到达那里时,它会在猎物周围移动,选择合适的地方挖掘和捕捉猎物。在后一种模式下,蜜獾利用导蜜鸟的引导直接定位蜂巢。


03.论文中算法对比图
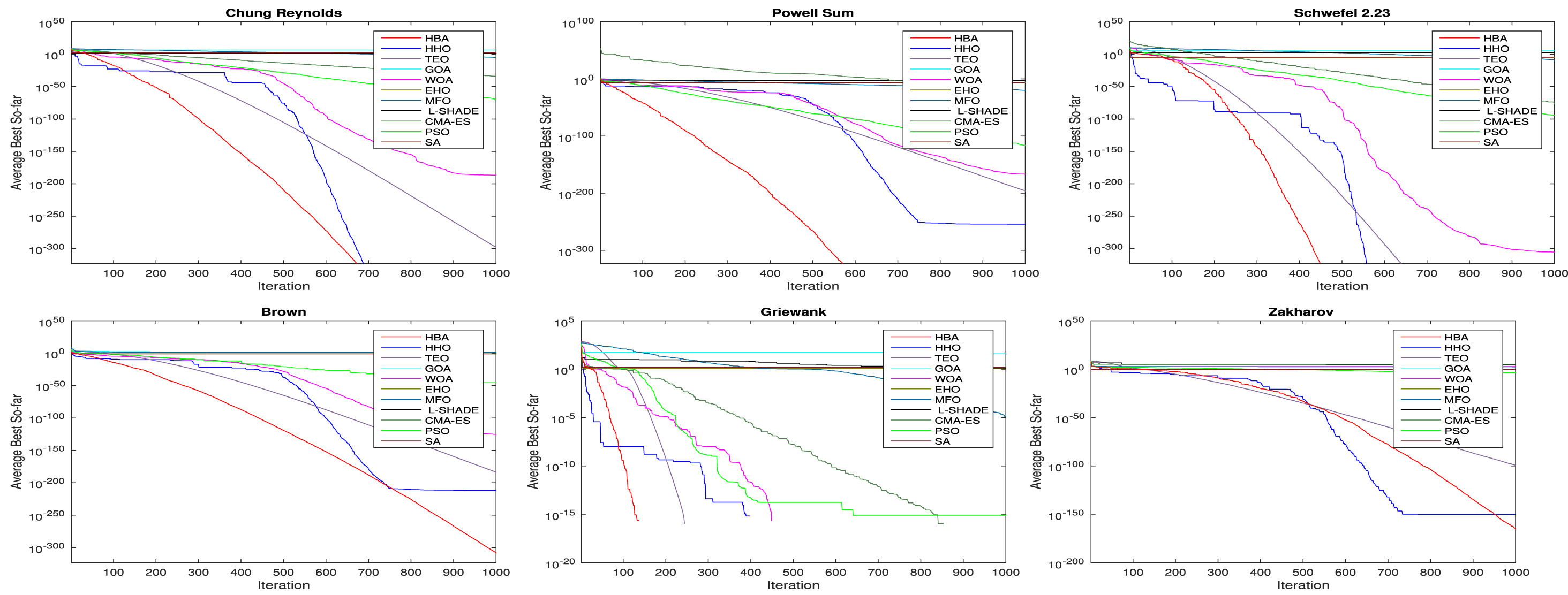
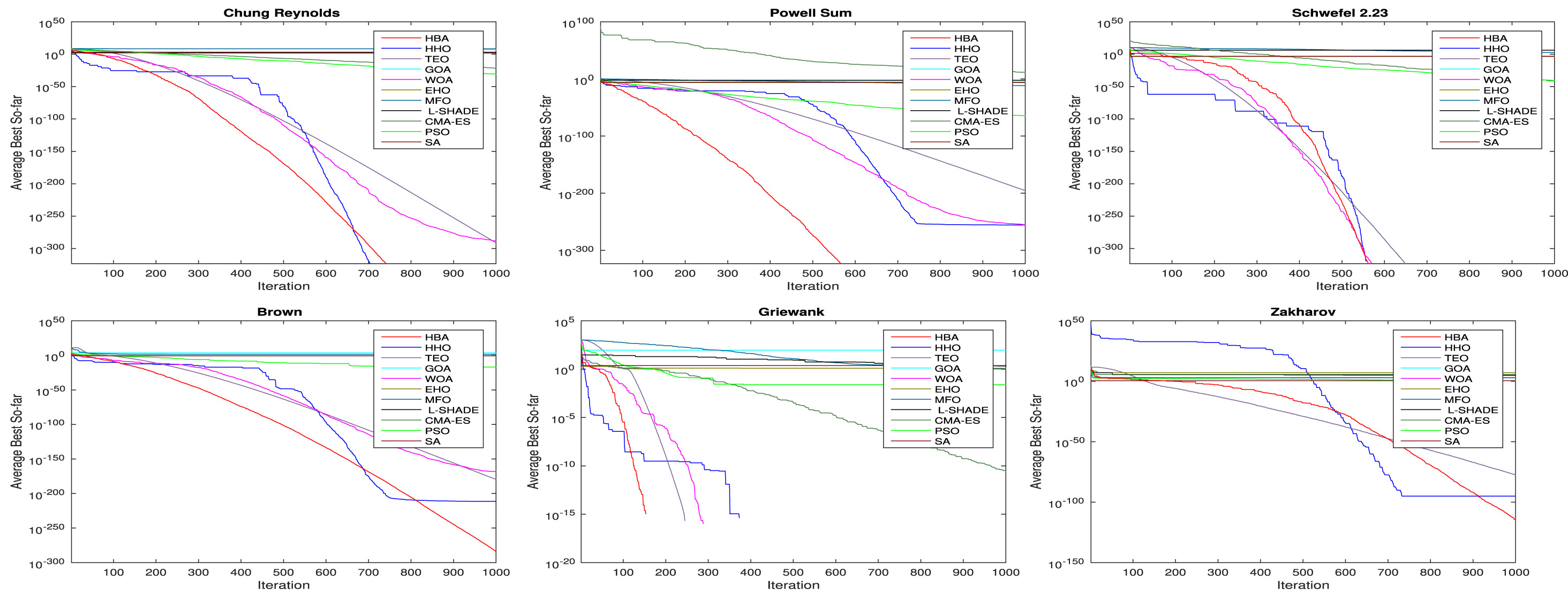
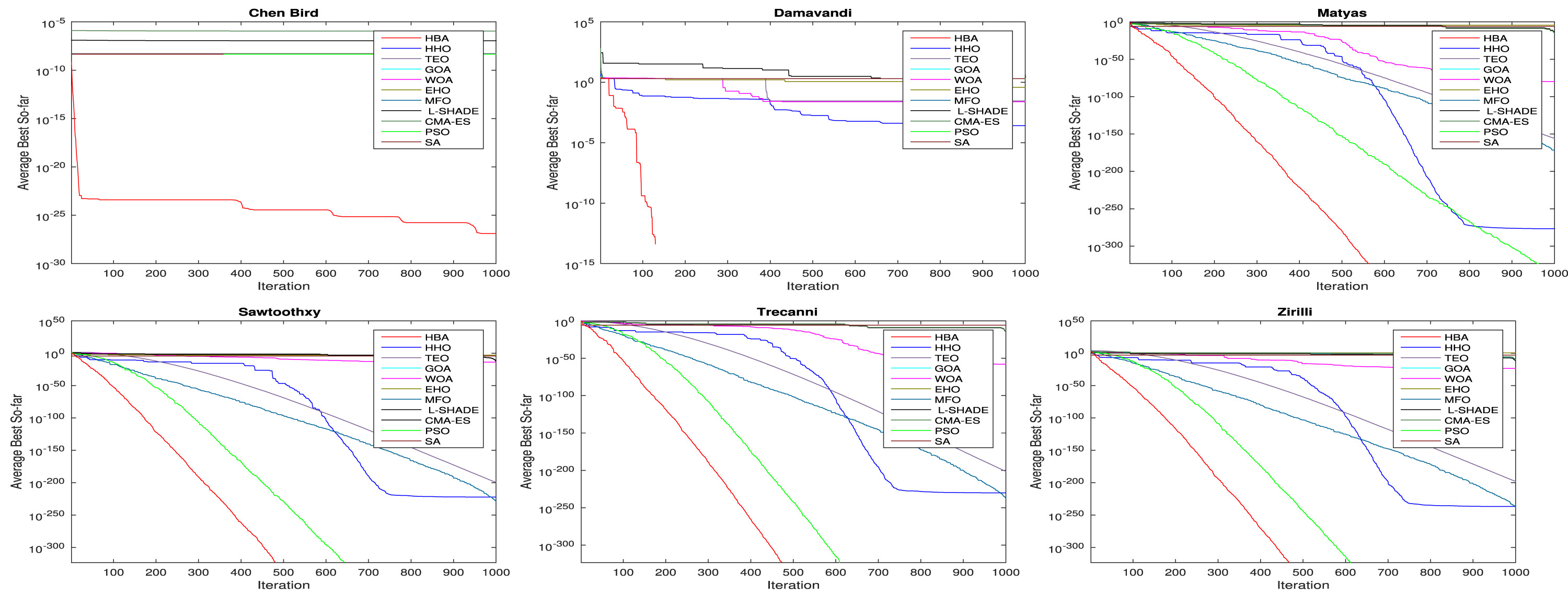
04.部分代码
function [Food_Score,Xprey,CNVG] = HBA(N,tmax,lb,ub,dim,objfunc)
beta = 6; % the ability of HB to get the food Eq.(4)
C = 2; %constant in Eq. (3)
vec_flag=[1,-1];
%initialization
X=initialization(N,dim,ub,lb);
%Evaluation
fitness = fun_calcobjfunc(objfunc, X);
[GYbest, gbest] = min(fitness);
Xprey = X(gbest,:);
for t = 1:tmaxalpha=C*exp(-t/tmax); %density factor in Eq. (3)I=Intensity(N,Xprey,X); %intensity in Eq. (2)for i=1:Nr =rand();F=vec_flag(floor(2*rand()+1));for j=1:1:dimdi=((Xprey(j)-X(i,j)));if r<.5r3=rand; r4=rand; r5=rand;Xnew(i,j)=Xprey(j) +F*beta*I(i)* Xprey(j)+F*r3*alpha*(di)*abs(cos(2*pi*r4)*(1-cos(2*pi*r5)));elser7=rand;Xnew(i,j)=Xprey(j)+F*r7*alpha*di;endendFU=Xnew(i,:)>ub;FL=Xnew(i,:)<lb;Xnew(i,:)=(Xnew(i,:).*(~(FU+FL)))+ub.*FU+lb.*FL;tempFitness = fun_calcobjfunc(objfunc, Xnew(i,:));if tempFitness<fitness(i)fitness(i)=tempFitness;X(i,:)= Xnew(i,:);endendFU=X>ub;FL=X<lb;X=(X.*(~(FU+FL)))+ub.*FU+lb.*FL;[Ybest,index] = min(fitness);CNVG(t)=min(Ybest);if Ybest<GYbestGYbest=Ybest;Xprey = X(index,:);end
end
Food_Score = GYbest;
end
function Y = fun_calcobjfunc(func, X)
N = size(X,1);
for i = 1:NY(i) = func(X(i,:));
end
end
function I=Intensity(N,Xprey,X)
for i=1:N-1di(i) =( norm((X(i,:)-Xprey+eps))).^2;S(i)=( norm((X(i,:)-X(i+1,:)+eps))).^2;
end
di(N)=( norm((X(N,:)-Xprey+eps))).^2;
S(N)=( norm((X(N,:)-X(1,:)+eps))).^2;
for i=1:Nr2=rand;I(i)=r2*S(i)/(4*pi*di(i));
end
end
function [X]=initialization(N,dim,up,down)
if size(up,2)==1X=rand(N,dim).*(up-down)+down;
end
if size(up,2)>1for i=1:dimhigh=up(i);low=down(i);X(:,i)=rand(N,1).*(high-low)+low;end
end
end04.本代码效果图
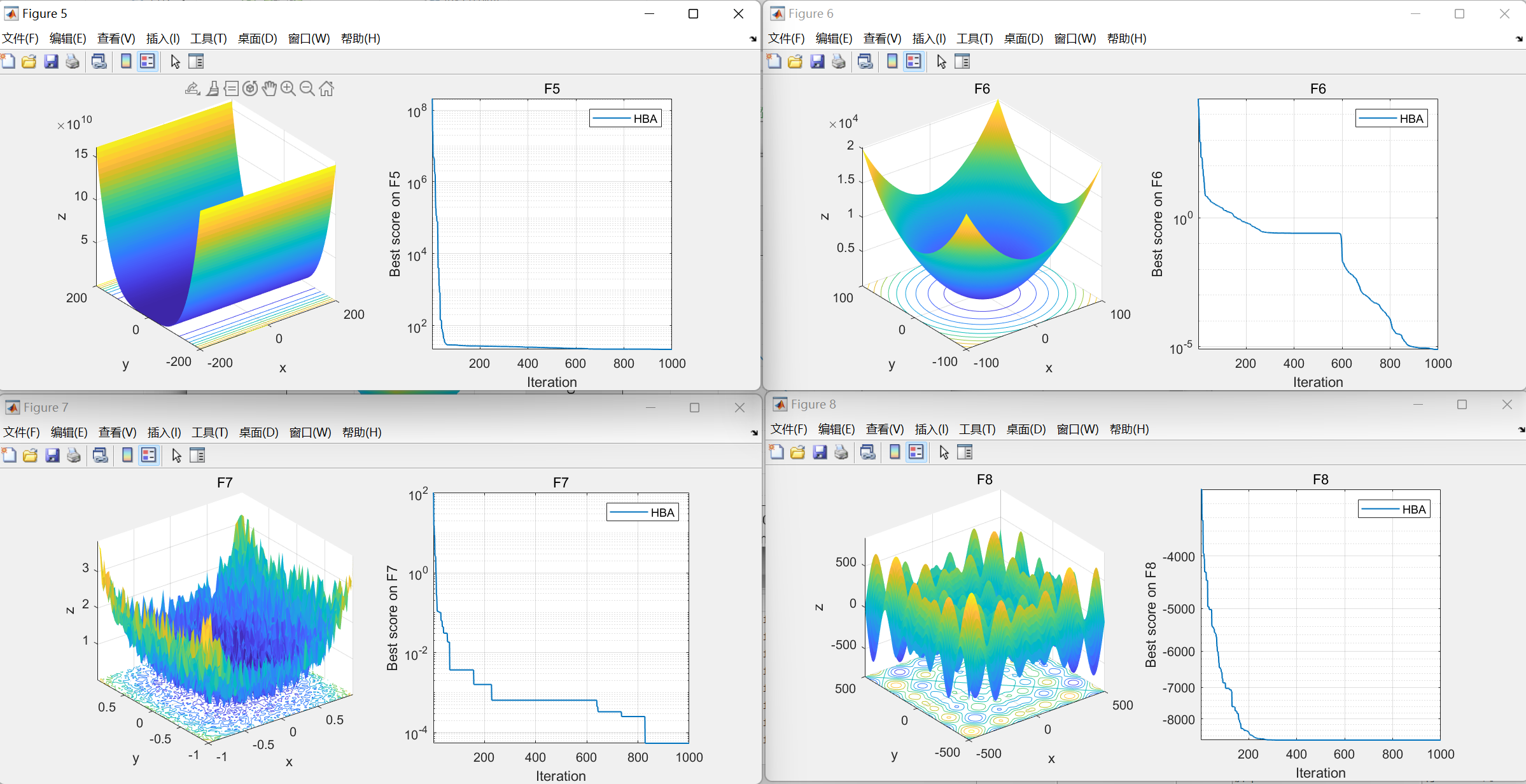
获取代码请关注MATLAB科研小白的个人公众号(即文章下方二维码),并回复智能优化算法本公众号致力于解决找代码难,写代码怵。各位有什么急需的代码,欢迎后台留言~不定时更新科研技巧类推文,可以一起探讨科研,写作,文献,代码等诸多学术问题,我们一起进步。