网站锚文本怎么做河南商城网站建设
DC-DC 和 LDO两者有何区别?
DC-DC转换器(直流-直流转换器)和LDO(低压差线性稳压器)都是用于电源管理的设备,但它们在原理和特性上有一些显著的区别:
·原理:
DC-DC转换器通过改变输入电压的形式(通常是电压升压或降压)来提供输出电压。它们使用开关元件(如MOSFET)以及电感和电容来实现电压的转换。
LDO则通过调整输入电压之间的差值来提供稳定的输出电压。它们通过调节一个可变电阻(通常是一个晶体管)来实现电压稳定。
效率:
由于DC-DC转换器利用了电感和电容存储能量,它们通常具有较高的效率,特别是在较大的电压转换范围内。
LDO的效率通常较低,特别是在输入和输出电压之间的差值(即压降)很大时,因为它们将多余的能量转化为热量散失。
适用范围:
DC-DC转换器通常用于需要大电压转换比的情况,如从汽车电池(12V)到低电压微处理器核心(1.2V或更低)。
LDO适用于要求不高的应用场景,例如当输入电压与输出电压接近时,或者需要较低的电源噪声和更简单的设计。
稳定性:
由于LDO的工作原理,它们通常具有更好的线性稳定性和低噪声。
DC-DC转换器可能受到开关频率、电感和电容等因素的影响,导致输出电压的一些波动。
成本和尺寸:
LDO通常比DC-DC转换器更简单,成本更低,并且尺寸更小。
DC-DC转换器可能需要更多的外部元件(如电感、电容)和复杂的控制电路,因此在成本和尺寸上可能更大。
总的来说,选择DC-DC转换器还是LDO取决于具体的应用需求,包括电源效率、成本、尺寸、稳定性和工作环境等因素。
LDO与DCDC这次给它彻底搞懂
EEPROM 和Flash 有何区别,什么情况下用哪种?
EEPROM(Electrically Erasable Programmable Read-Only Memory)和Flash都是用于存储数据的非易失性存储器(Non-Volatile Memory),但它们有一些区别,以及在不同情况下适合使用的特点:
-
擦写和擦除:
- EEPROM可以单独擦除和编程每个字节,而不需要擦除整个存储器。这意味着它可以在不影响其他数据的情况下更新单个字节。
- Flash存储器通常需要按块(通常是扇区或页)擦除,然后才能对数据进行更新。这意味着在更新数据时需要擦除整个块,而不是单个字节。
-
速度:
- EEPROM的擦写速度通常较慢,因为它需要针对每个字节进行擦除和编程。
- Flash存储器通常具有更快的擦写速度,因为它可以按块擦除,而不是单个字节。
-
耐久性:
- EEPROM通常具有更高的擦写/擦除次数,因为它可以单独擦除和编程每个字节,不会影响到其他数据。
- Flash存储器的耐久性通常较低,因为在擦写时需要擦除整个块,这可能会导致存储器块的磨损。
-
应用场景:
- EEPROM适用于需要频繁更新少量数据的应用,例如存储配置参数或小型日志数据。
- Flash存储器适用于需要大容量数据存储和较快擦写速度的应用,例如固件存储、操作系统存储、嵌入式应用程序等。
-
成本:
- 由于EEPROM的制造复杂度较低,成本通常较低。
- Flash存储器的成本通常较高,特别是在较大容量的情况下。
综上所述,选择使用EEPROM还是Flash取决于应用的具体需求,包括擦写频率、速度要求、数据大小和成本考虑。
串口通讯波特率有9600,有的是115200,在选择通信速率的时候是按照什么标准进行选择的?
选择串口通讯波特率时,通常需要考虑以下几个因素:
-
通信需求:首先要考虑的是通信双方的需求,包括数据传输速度和实时性。如果需要传输大量数据或者需要高实时性,可能需要选择较高的波特率,如115200或更高。
-
硬件支持:要确保通信双方的硬件支持所选择的波特率。有些硬件可能只支持特定的波特率范围,因此需要根据硬件的能力来选择合适的波特率。
-
通信距离:通信距离也是一个考虑因素。较高的波特率可能在长距离通信时出现信号衰减或失真,因此在长距离通信时可能需要降低波特率。
-
环境噪声:如果通信环境存在较多的电磁干扰或噪声,较低的波特率可能更可靠,因为它们对干扰更具抗性。
-
功耗:通信速率可能会影响设备的功耗。较高的波特率通常需要更多的能量来维持通信,因此在对功耗有限制的情况下,可能需要选择较低的波特率。
综合考虑以上因素,可以根据具体的通信需求和环境特点来选择合适的波特率。通常情况下,如果没有特殊要求,9600和115200是比较常见的波特率选择。
分析电路的功能,以及Vref输出结果?
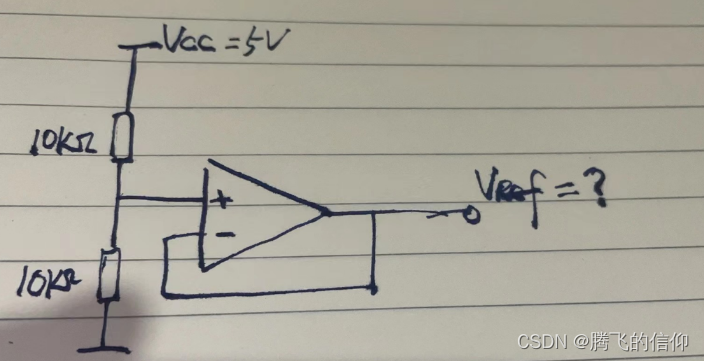
电压跟随器,输出2.5V
电压跟随器在电路中的作用,只是跟随性能会更好、隔离效果更好(输入电阻更小)、带负载能力更强(输出电阻更小)。
linux中进程、线程的区别是什么?
在Linux系统中,进程(Process)和线程(Thread)是操作系统中的两个基本概念,它们有着以下区别:
- 资源分配:
进程是系统资源分配的基本单位,拥有独立的内存空间、文件描述符、堆栈等。
线程是进程内的执行单元,共享同一进程的资源,包括内存空间和文件描述符等。多个线程共享进程的地址空间,因此线程之间的通信和数据共享更加方便快捷。
- 切换开销:
进程之间的切换开销较大,因为切换进程需要切换整个进程的上下文环境,包括内存空间、寄存器状态等。
线程之间的切换开销相对较小,因为线程共享同一进程的地址空间和资源,切换时只需切换线程的私有数据。
- 并发性:
进程之间是独立的,每个进程都有自己的地址空间和资源,因此进程之间的并发性较低。
线程之间共享进程的资源,因此线程之间的并发性更高,可以更方便地进行数据共享和通信,提高系统的并发性能。
- 创建和销毁:
创建和销毁进程的开销较大,因为需要分配和释放独立的地址空间和资源。
创建和销毁线程的开销相对较小,因为线程共享进程的资源,只需分配和释放线程的私有数据即可。
- 安全性:
进程之间的安全性更高,因为进程之间是独立的,一个进程的崩溃不会影响其他进程。
线程之间共享进程的资源,因此线程之间的安全性更低,一个线程的错误可能会影响到其他线程。
综上所述,进程和线程在资源分配、切换开销、并发性、创建销毁、安全性等方面有着不同的特点和应用场景,开发人员需要根据实际需求选择合适的进程或线程来进行程序设计和开发。
C语言,不适用第三个变量实现,两个变量的交换,a=3,b=5
在C语言中,可以通过使用算术运算符或者位操作来实现两个变量的交换,而不需要使用第三个变量。以下是两种常见的方法:
a = a + b;
b = a - b;
a = a - b;使用位操作
a = a ^ b;
b = a ^ b;
a = a ^ b;这两种方法都可以在不使用第三个变量的情况下实现两个变量的交换。第一种方法利用了加法和减法的性质,而第二种方法利用了异或运算的性质
C语言和C++的struct有什么区别?

代码分析
#include <stdio.h>int main(void){int a[5] = {1,2,3,4,5};int *p = (int *)(&a[0] + 1);printf("%d\r\n",*(a+1));printf("%d\r\n",*(p-1));return 0;
}
这段代码涉及指针运算和数组的地址计算,我们来逐步分析:
int a[5] = {1,2,3,4,5};:定义了一个包含5个整数的数组a,初始化为{1,2,3,4,5}。
int *p = (int *)(&a[0] + 1);:将指针p指向数组a的第一个元素的地址(&a[0]),然后执行指针运算,将p向后移动了1个整数大小的偏移量(即a[1]的地址)。需要注意的是,由于是将指针的类型强制转换为int类型的指针,所以指针运算的单位是int的大小。
printf(“%d\r\n”,*(a+1));:输出a数组中索引为1的元素的值,即2。
printf(“%d\r\n”,*(p-1));:输出指针p所指向的地址向前移动一个整数大小的偏移量的元素的值,即a[0]的值,也就是1。
综上所述,程序的输出结果应该是:
2
1TCP/UDP有什么区别?

OSI七层模式是什么?TCP/UDP在哪一层?

RS485主机和多个从机的数据链路是如何通讯设计的

ADC滤波算法
六种常用滤波算法代码实现及效果