网站建设部分费用会计科目买的网站模板里面是什么
“超能力”数据库~拿来即用,应用开发人员再也不用为撰写API而发愁。MemFire Cloud 为开发者提供了简单易用的云数据库(表编辑器、自动生成API、SQL编辑器、备份恢复、托管运维),很大地降低开发者的使用门槛。
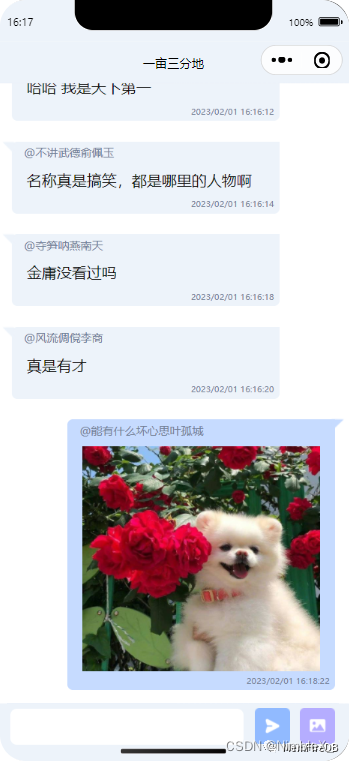
本示例是一个可以实现多人互动的角色扮演聊天室的微信小程序(web版传送门:Web开发示例–多人聊天互动空间),小程序后端服务使用了MemFire Cloud,其中使用到的MemFire Cloud功能包括:
其中使用到的MemFire Cloud功能包括:
- 云数据库:存储聊天室小程序数据表的信息。
- 即时API:创建数据表时会自动生成 API。
- 云存储:存储用户发布帖子中的图片。
- Realtime:轻松构建任何类型的实时应用程序

创建应用
目的:通过创建的一个MemFire Cloud应用来获得数据库、云存储等一系列资源,并将获得该应用专属的API访问链接和访问密钥,用户可以轻松的调用API接口与以上资源进行交互。
登录MemFire Cloud, 在“我的应用”页面创建一个新应用
创建数据表
创建messages表
建表操作如下:
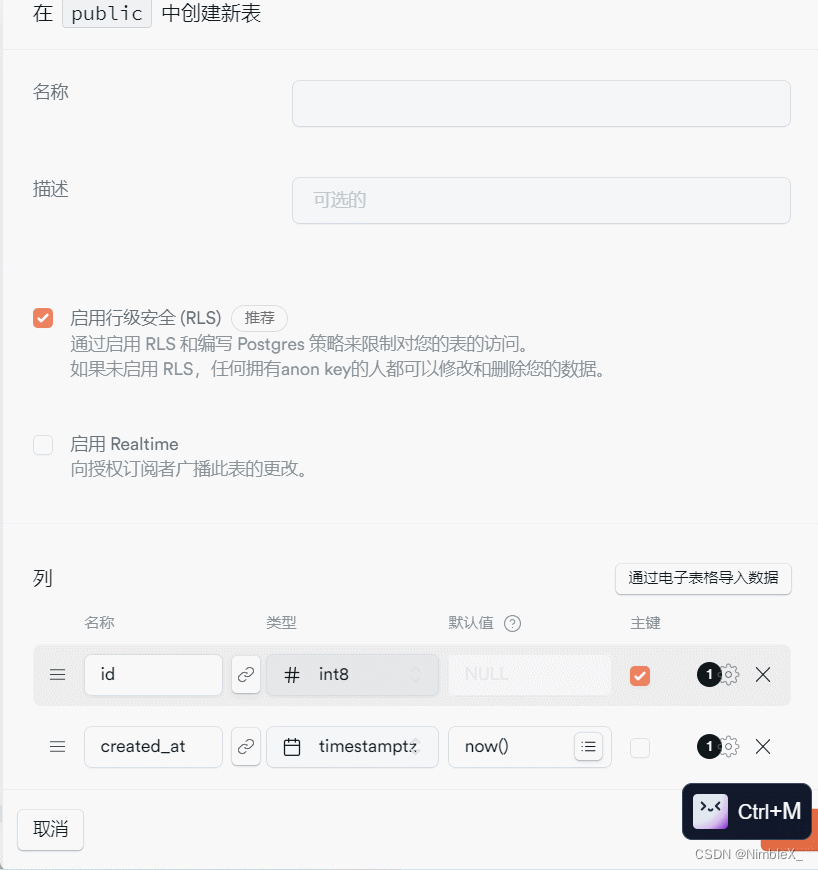
在“表编辑器”页面,点击“新建表”,创建messages表。messages表主要记录用户发送的每一条信息,表结构字段如下:
| 名称 | 类型 | 描述 |
|---|---|---|
| id | bigint | 主键,自动为列分配一个连续的唯一编号,唯一标识ID |
| username | varchar | 用户名 |
| bgColor | varchar | 头像背景颜色 |
| created_at | timetamptz | 创建时间 |
| text | text | 消息 |
sql建表语句
CREATE TABLE messages (id bigint GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,username VARCHAR NOT NULL,bgColor VARCHAR NOT NULL,text TEXT NOT NULL,timestamp timestamp default now() NOT NULL
);
创建策略
接下来,需要给messages表创建两条策略,分别是允许所有用户可以查询和插入messages表数据,在“SQL执行器”页面,点击“新查询”按钮,新建一个SQL Query,执行以下操作:
alter table public.messages enable row level security;-- 启用对所有用户的查询数据访问
create policy "Enable access to all users" on public.messages for
select using (true);-- 启用对所有用户的插入数据访问
create policy "Enable insert for all users" on public.messages for
insert with check (true);
启用Realtime
常用的启用Realtime功能有两种方式:
①在表编辑器页面,创建数据表时,勾选“启用Realtime”,即可启用;
② 在“数据库->Replication”页面,启用Realtime,可以选择Realtime监听数据表的‘插入’、‘更新’、‘删除’、‘截断’操作,可以根据业务自身需求勾选,这里我们需要启用全部操作。点击‘1张表’按钮后,进入数据表列表,点击message表的开关按钮,启用Realtime功能。
创建bucket
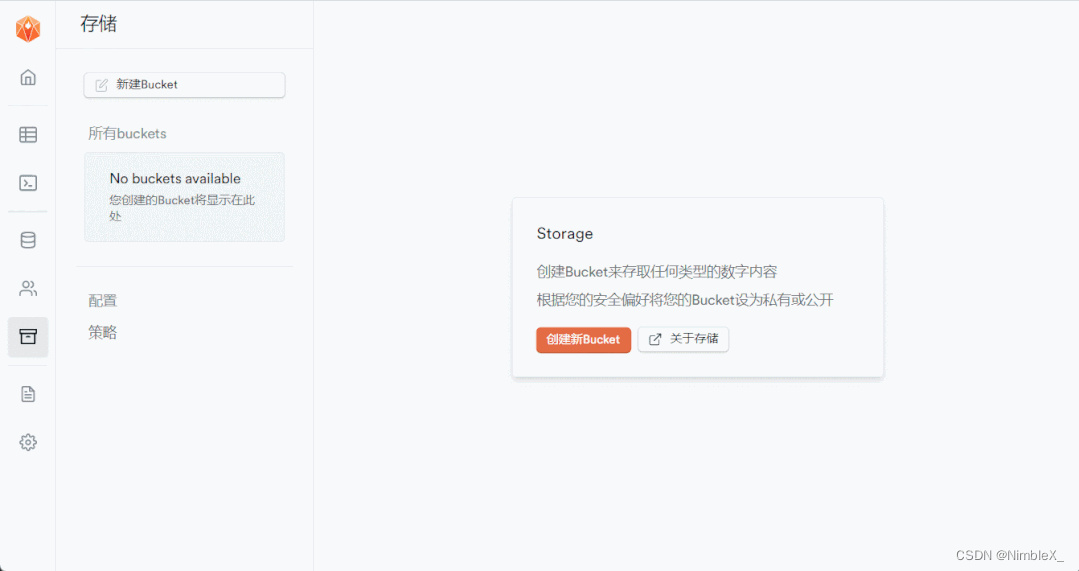
1.新建images存储桶
点击‘存储’图标菜单,点击‘创建新bucket’,创建images存储桶
2.创建策略
接下来,给images存储桶创建一个策略,允许所有的用户在聊天中发送图片。
-- Secure the bucket
CREATE POLICY "允许任何用户发送图片1ffg0oo_0" ON storage.objects FOR INSERT TO public WITH CHECK (bucket_id = 'images' );
注册小程序
以上是我们在MemFire Cloud上配置的全部步骤,接下来是在微信开发者工具上操作了。
「如果您还未注册过小程序,请参考官方步骤注册小程序(只需要通过您的邮箱注册一个小程序获得一个appid,然后下载一个微信开发工具即可)」
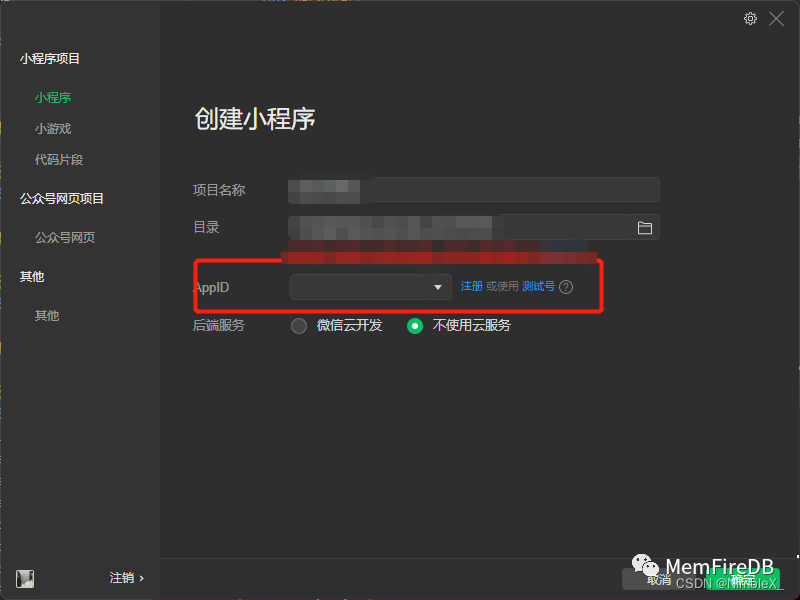
用微信开发者工具点击导入项目
选择目录是下载好的小程序项目的目录,AppID为您在微信公众平台注册小程序获得的专属appid。
构建npm
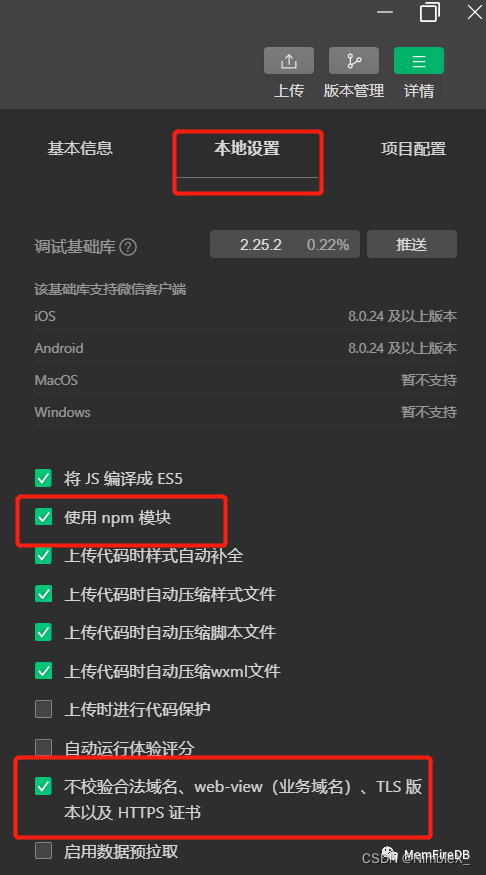
在右侧详情里面的本地设置把“使用npm模块”和“不校验合法域名”勾上。
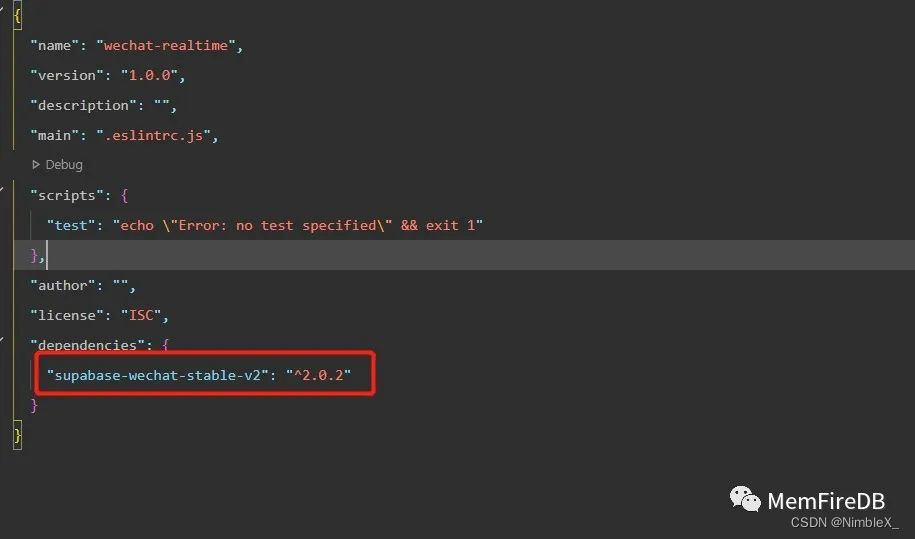
打开终端,在项目根目录下执行如下命令 (小程序需要的MemFire Cloud的微信小程序SDK已经存在package.json里,可以直接安装全局依赖)。
npm init
npm install
点击开发者工具中的菜单栏:工具 /构建 npm
这一步npm就构建完成了,我们需要的依赖也已经下载好了,根目录下会多出两个文件,如下图。
获取 API密钥
接下来需要创建一个可以访问应用程序数据的客户端,小程序使用了MemFire Cloud 微信小程序SDK包,使用他生态里提供的功能(登录、注册、增删改查等)去进行交互。创建一个可以访问微信小程序数据的客户端需要接口的地址(URL)和一个数据权限的令牌(ANON_KEY),我们需要去应用的首页去获取这两个参数然后配置到lib/supabase.js里面去。
lib/supabase.js
import { createClient } from 'supabase-wechat-stable-v2'
const url = ""
const key = ""export const supabase = createClient(url, key)
回到MemFire Cloud首页,在应用/首页页面,获取服务地址以及token信息,只需要从首页中获取URL接口地址和anon的密钥。
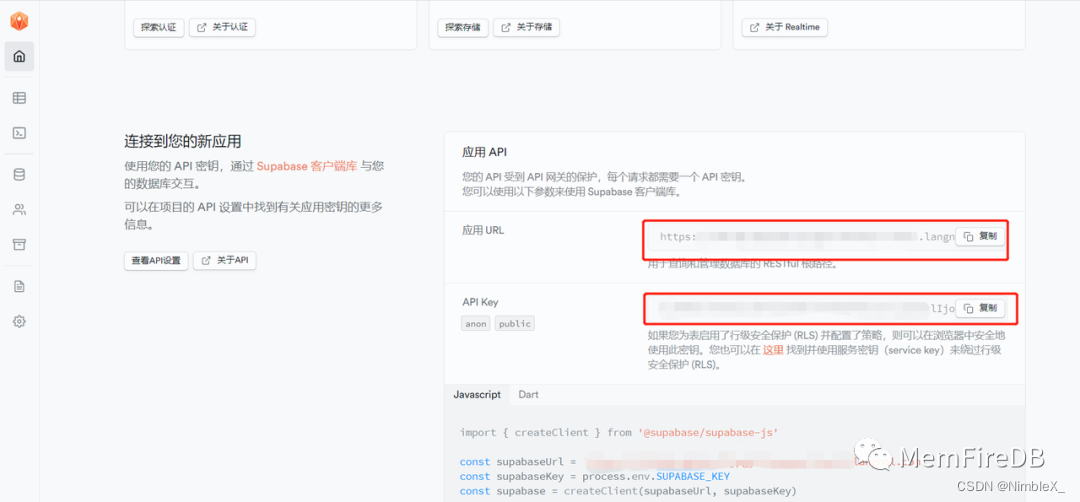
「Anon(公开)密钥是客户端API密钥。它允许“匿名访问”您的数据库,直到用户登录。登录后,密钥将切换到用户自己的登录令牌。这将为数据启用行级安全性。」
编译小程序