珠三角做网站企业查询系统官网天眼查
网络爆炸性地发展,网络环境也日益复杂和开放,同时各种各样的恶意威胁和攻击日益增多,其中网站被CC也是常见的情况。
CC攻击有什么危害呢?
被CC会导致:
1.访问速度变慢:网站遭受CC攻击后,由于服务器资源被攻击流量占据,且带宽出现拥堵,网站打开的速度就会变慢。
2.被搜索引擎降权:受CC攻击的影响,网站的访问会出现反常情况,导致网站无法被搜索引擎抓取,这就会影响网站在搜索引擎的排名。
3.影响用户体验:一旦服务器资源被侵占,网站的加载速度就会延迟,影响用户的访问体验。
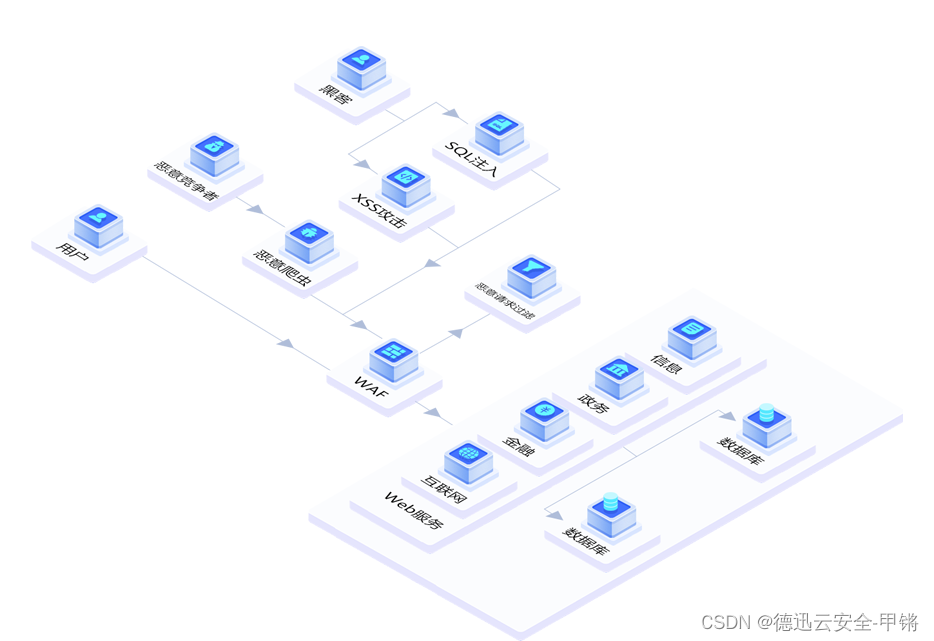
针对网站被CC我们应该怎么办?
1.取消域名绑定:一般的CC攻击都是通过将攻击对象设置为域名,然后再进行攻击。可以在IIS上取消绑定,那么网站也就不会再被模拟用户访问。
2.设置黑白名单:通过日志统计观察,确定发出攻击的IP,通过后台设置黑名单的形式去屏蔽某个IP段的形式,去抵御一些小型的攻击。
3.更改Web端口:一般情况下,Web服务器是通过80端口进行对外服务的,如果攻击者默认了该端口进行攻击,那么进行修改的话也可以有效避免。
4.更换服务器:使用德迅云安全稳定服务器,服务器自带智能防护CC策略,自动触发式拦截屏蔽CC。
5.使用SCDN:使用德迅安全加速CDN(SCDN)可以将网站内容缓存在全国分布的节点上,分散流量并减轻源服务器的压力,同时可以提供DDoS攻击防护。
6.加强网络安全措施:确保服务器和网络设备的安全性,及时更新防火墙规则,限制非法入侵;安装强大的入侵检测系统(IDS)和入侵防御系统(IPS),监控并及时阻止攻击行为。
7.配置负载均衡器:将网站流量分散到多台服务器上,这样即使一台服务器遭受攻击,其他服务器还可以正常运行,提高了整个网站的抗攻击能力。