服装 产品展示网站模板wordpress与微信教程 pdf
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、点阵是什么?
- 1.点阵的原理
- 2. 3*3 点阵显示原理
- 3. 8*8点阵实物图
- 4. 8*8点阵内部原理图
- 5. 16*16点阵实物图,显示原理
- 二、使用步骤
- 1.先看原理图,确定点阵是8*8 16*16 ,共阴,共阳?
- 2.写代码
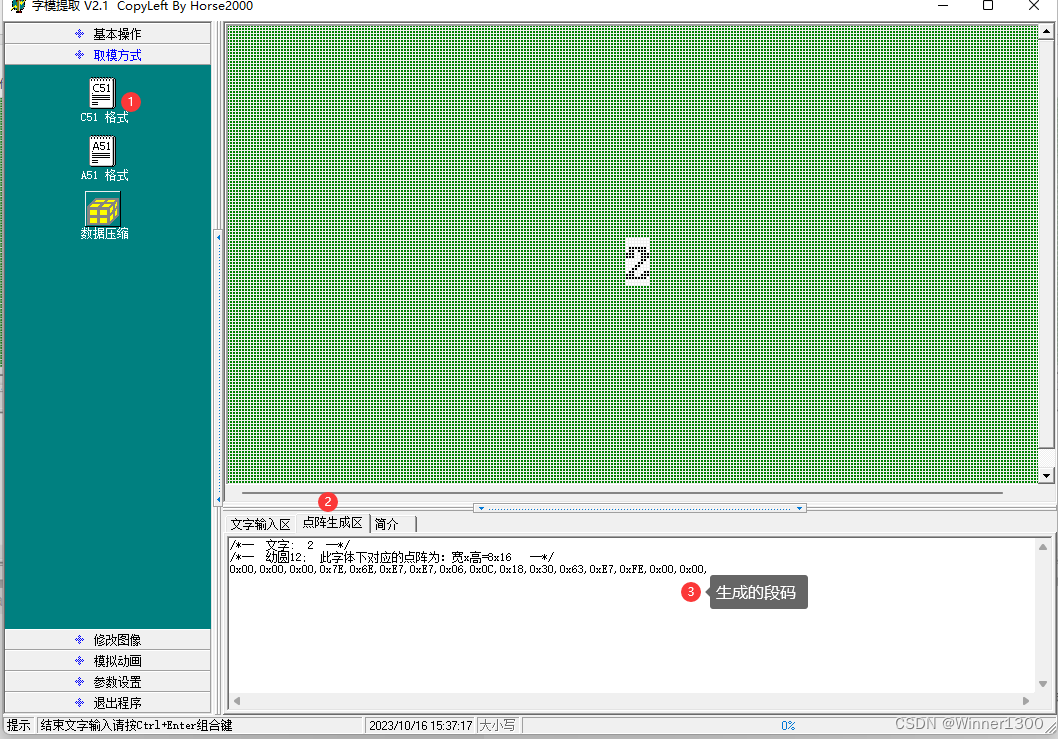
- 核心问题,段码怎么来?
- 三、实物操作
- 1.原理图
- 2.编程思路
- 四、 书上的代码讲解
- 总结
前言
学习了数码管的静态和动态显示,利用动态数码管显示的原理,搞定点阵。
一、点阵是什么?
1.点阵的原理
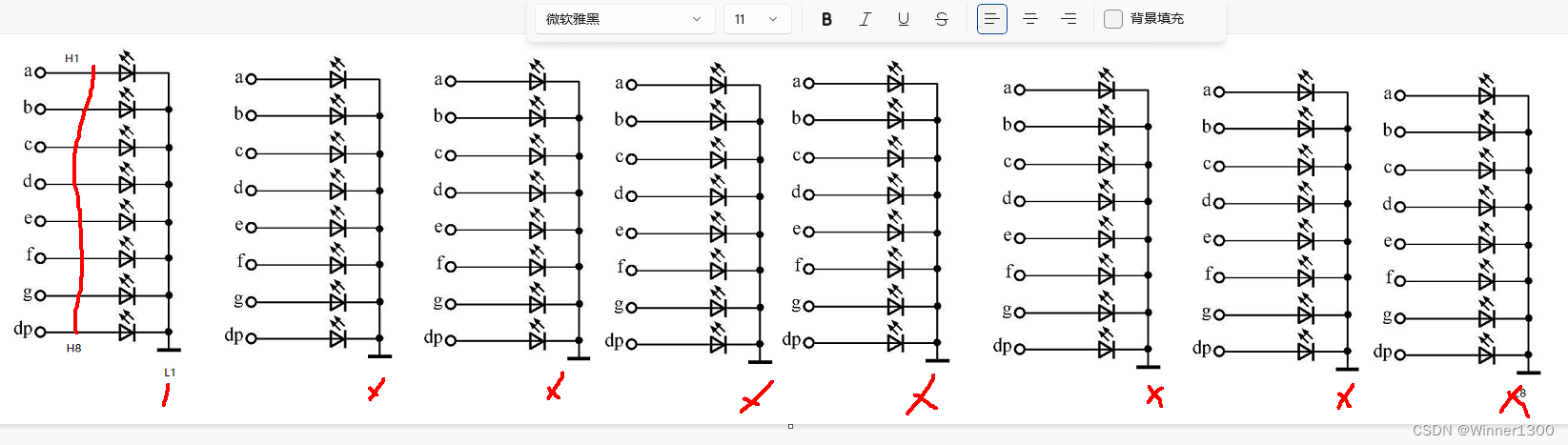
2. 3*3 点阵显示原理
3. 8*8点阵实物图

4. 8*8点阵内部原理图

5. 16*16点阵实物图,显示原理
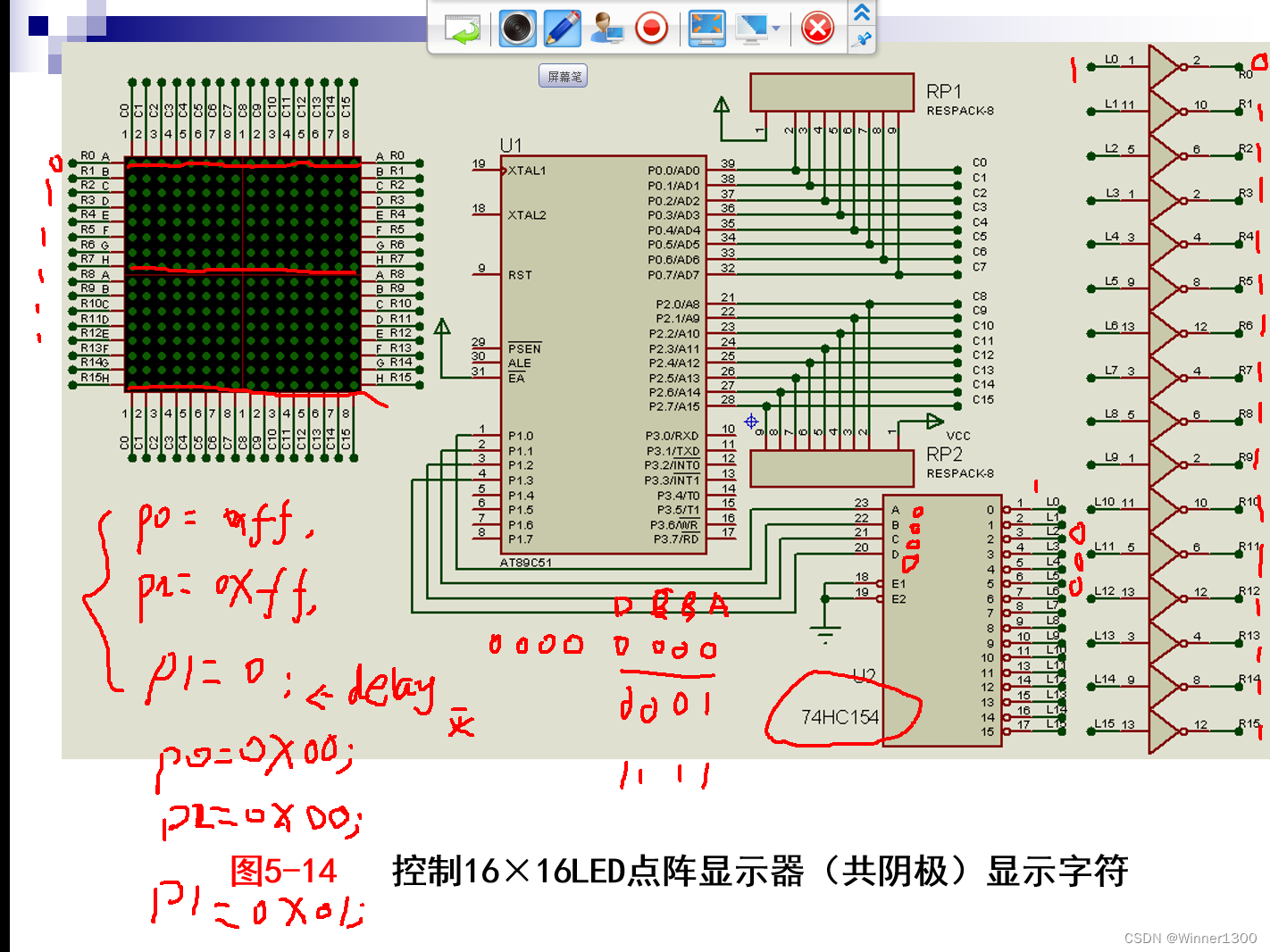
二、使用步骤
1.先看原理图,确定点阵是88 1616 ,共阴,共阳?
代码如下(示例):
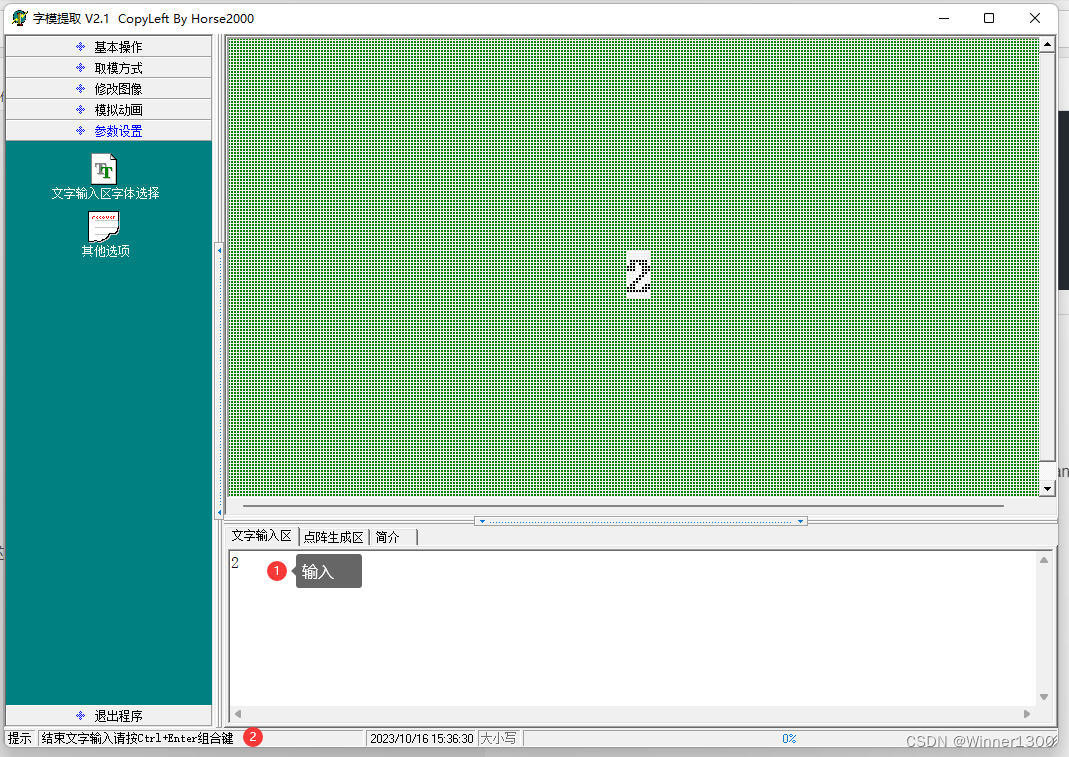
取段码:用专门的软件。
2.写代码
代码如下(示例):
逐行:第一行
1.先给段码
P0=0X?
P2=0X?
P1=0X00;第一行
1.先给段码
P0=0X?
P2=0X?
P1=0X01;0000~1111 0-15for(i=0;i<16;i++)
{P0=0X?P2=0X?P1=i;delay(?);P0=0X00;P2=0X00;}核心问题,段码怎么来?
三、实物操作
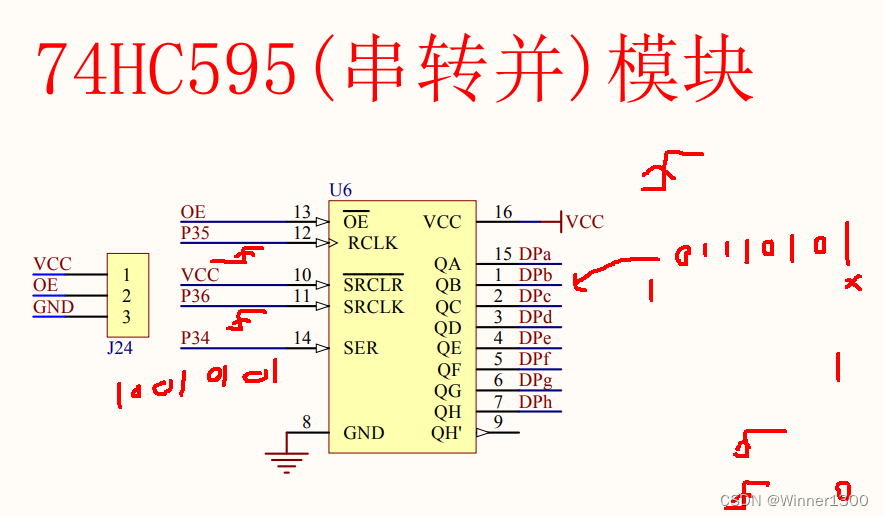
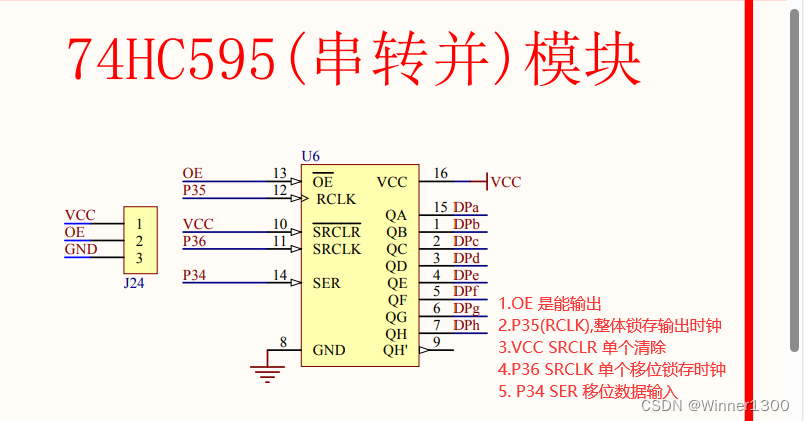
1.原理图

2.编程思路
- 段码 P0=0X?
- 位选
P35 pclk
P36 srclk
P34 SER
J24 接 GND
P35_RCLK
P34_data
P36_SRCLK
一次移位
P34_data=1;
P36_SRCLK=0;
P36_SRCLK=1;八次移位:
最简单的方法将上面的代码赋值八次
P34_data=?; // 是0 给00,是1给1
P36_SRCLK=0;
P36_SRCLK=1;
........P35_RCLK=0;
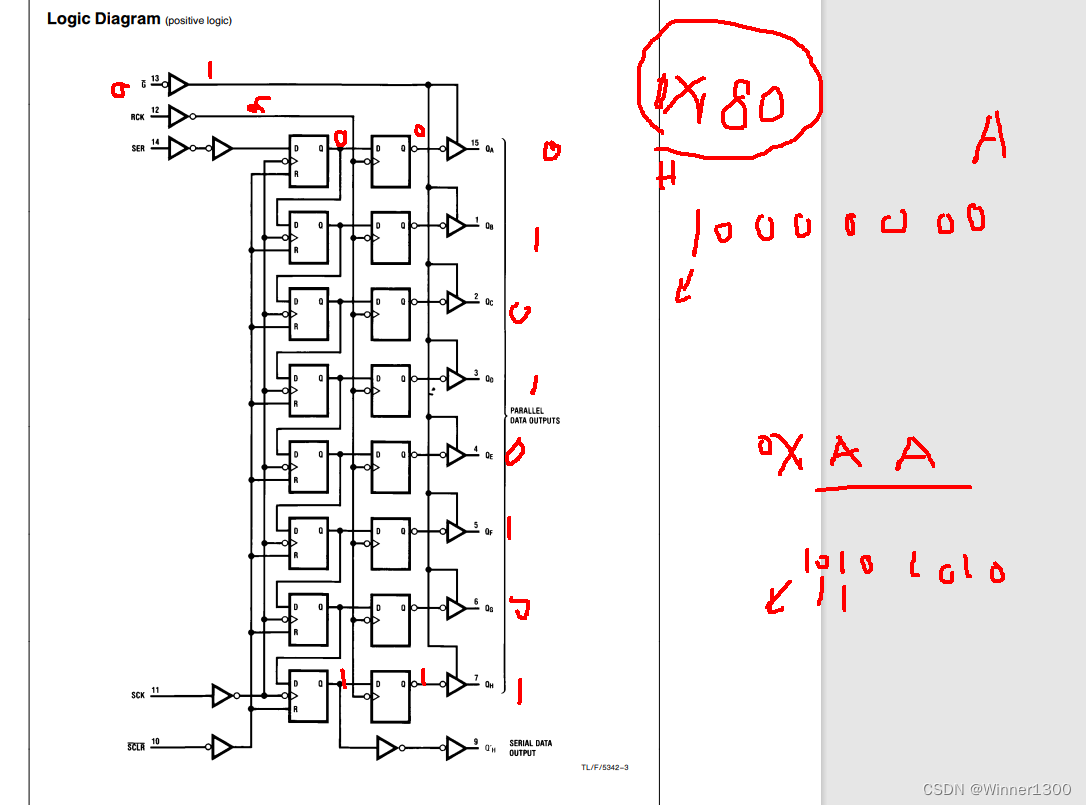
P35_RCLK=1;//发送 x =0x01 第一行// 0000 0001
// 1000 0000
&
//= 0000 0000//x =x<<1;// 0000 0010for(i=0;i<8;i++)
{if((x&0x80)==0){P34_data=0; // 是0 给00,是1给1}esle{P34_data=1; // 是0 给00,是1给1}P36_SRCLK=0;P36_SRCLK=1;x=x<<1;}
P35_RCLK=0;
P35_RCLK=1;P36_SRCLK=0;
P35_RCLK=0;//发送0x02 第二行 for(i=0;i<8;i++)
{P34_data=?; // 是0 给00,是1给1P36_SRCLK=0;P36_SRCLK=1;}
P35_RCLK=0;
P35_RCLK=1;P36_SRCLK=0;
P35_RCLK=0;简化的方法:
// 1000 0000
// 1 000 0000 0for(i=0;i<8;i++)
{X=X<<1;P34_data=CY; // 是0 给00,是1给1P36_SRCLK=0;P36_SRCLK=1;}
P35_RCLK=0;
P35_RCLK=1;P36_SRCLK=0;
P35_RCLK=0;
P0=0X?
HC595(0X01)temp=0x01;
for(i=0;i<8;i++)
{P0=0X?HC595(temp) //0x01temp=temp<<1;delay();P0=0X?//,灭
}
四、 书上的代码讲解


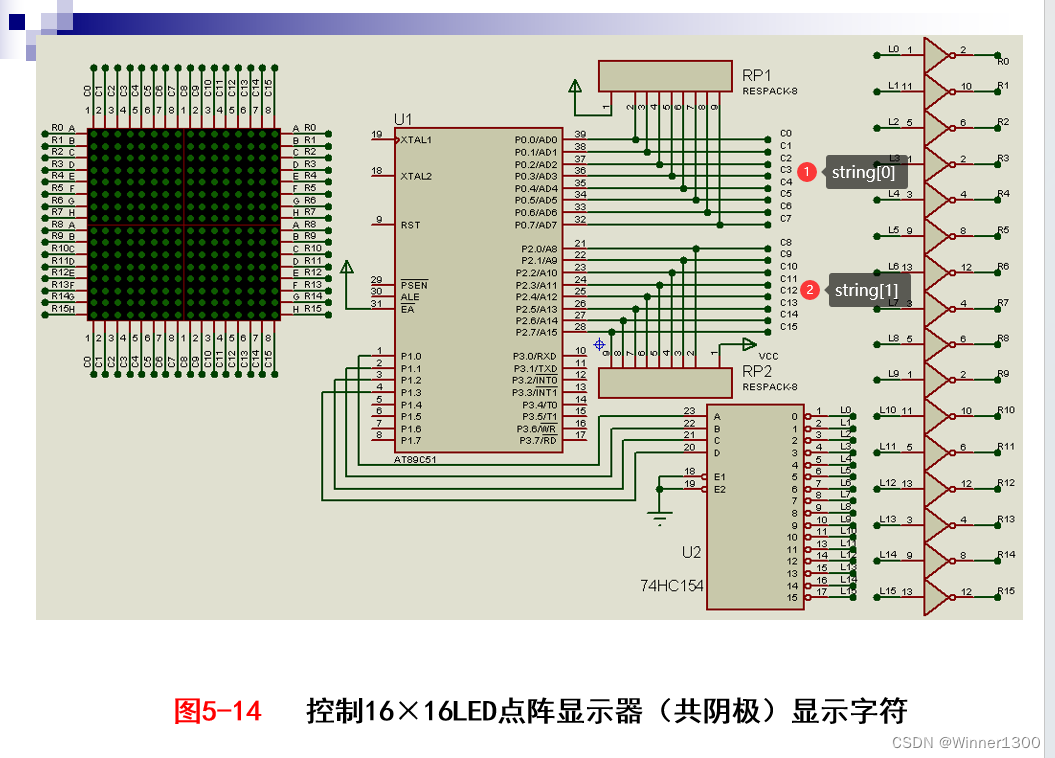
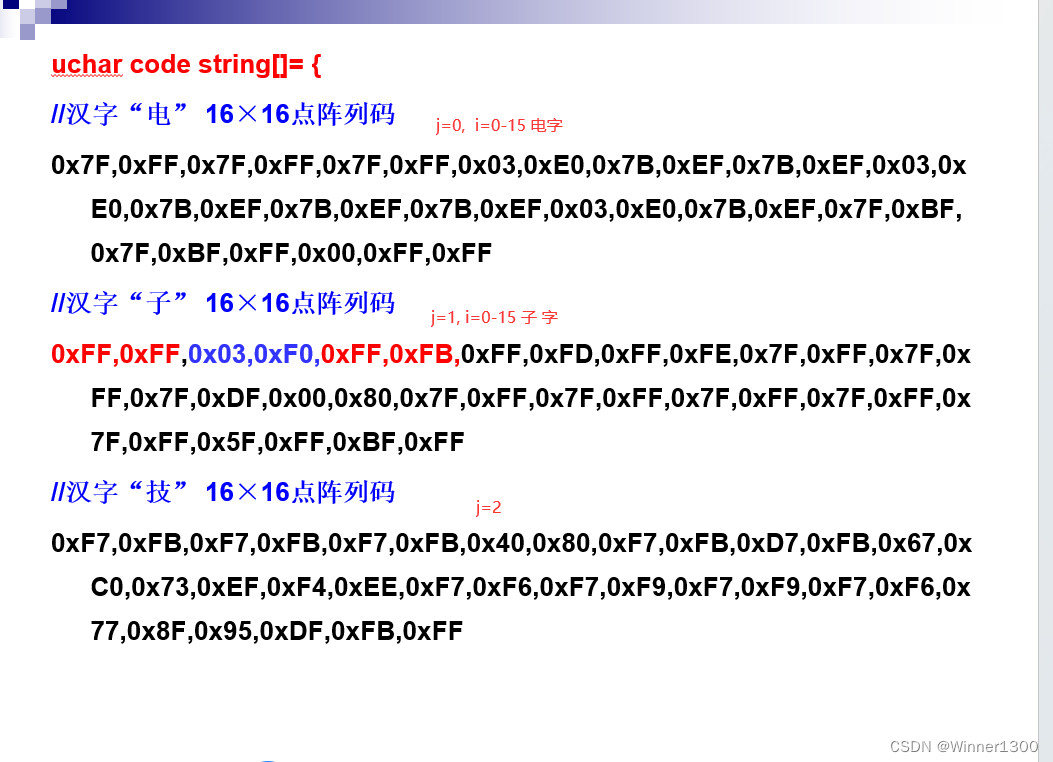
改变j显示不同的汉字,改变i显示不同行的段码;
n的讲解

总结
利用动态数码管显示的原理,用点阵显示字符。