建站公司做的网站侵权了网站seo怎么优化
数据仓库的数据分层通常包括以下几层:
- ODS层:存放原始数据,如日志数据和结构化数据。
- DWD层:进行数据清洗、脱敏、维度退化和格式转换。
- DWS层:用于宽表聚合值和主题加工。
- ADS层:面向业务定制的应用数据层。
- DIM层:一致性维度建模,包括低基数和高基数维度数据。
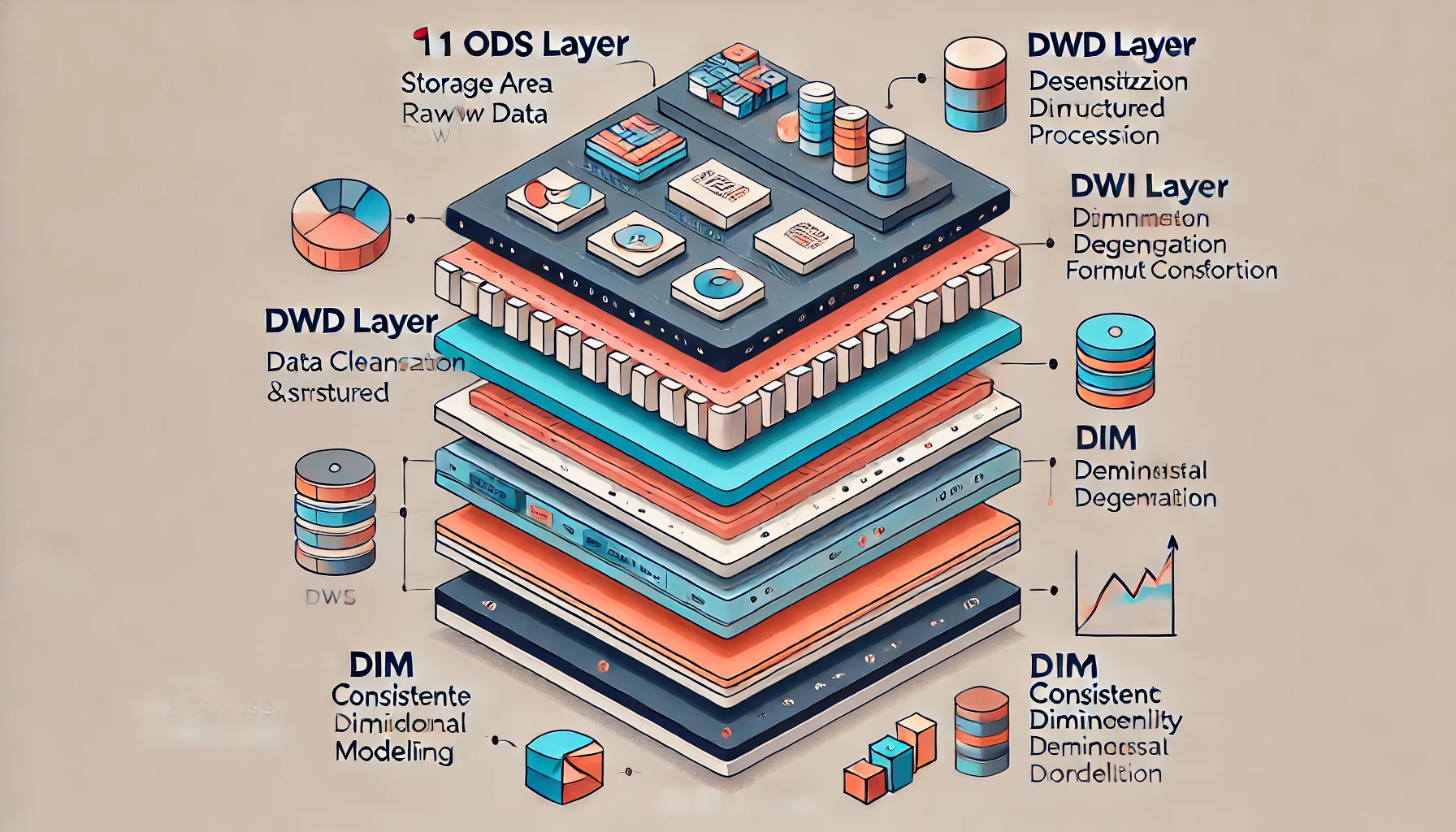
为了更好地理解数据仓库的各个方面,我们以一个广告投放平台为例,详细说明各个层级的数据处理和使用,并附带一些代码示例。
1. ODS层
ODS(Operational Data Store)层存放的是原始数据。比如,广告点击日志数据。
示例数据:
{"log_id": "12345","user_id": "67890","ad_id": "54321","timestamp": "2023-06-21T12:00:00Z","action": "click","cost": 0.5
}
2. DWD层
DWD(Data Warehouse Detail)层进行数据清洗、脱敏、维度退化和格式转换。
数据清洗代码示例(使用PySpark):
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, from_unixtime# 创建SparkSession
spark = SparkSession.builder.appName("DWD Layer").getOrCreate()# 读取ODS层数据
ods_data = spark.read.json("hdfs://path/to/ods/data")# 数据清洗
dwd_data = ods_data.withColumn("timestamp", from_unixtime(col("timestamp")))# 写入DWD层
dwd_data.write.mode("overwrite").json("hdfs://path/to/dwd/data")
3. DWS层
DWS(Data Warehouse Service)层用于宽表聚合和主题加工。
宽表聚合代码示例:
from pyspark.sql.functions import sum# 聚合用户点击行为数据
dws_data = dwd_data.groupBy("user_id").agg(sum("cost").alias("total_cost"))# 写入DWS层
dws_data.write.mode("overwrite").json("hdfs://path/to/dws/data")
4. ADS层
ADS(Application Data Store)层面向业务定制的应用数据层。比如,计算每个广告的总点击次数。
业务定制数据处理代码示例:
from pyspark.sql.functions import count# 计算每个广告的总点击次数
ads_data = dwd_data.groupBy("ad_id").agg(count("action").alias("click_count"))# 写入ADS层
ads_data.write.mode("overwrite").json("hdfs://path/to/ads/data")
5. DIM层
DIM(Dimension)层用于一致性维度建模。
维度建模示例:
# 读取广告信息维度数据
ad_info = spark.read.json("hdfs://path/to/dim/ad_info")# 读取ADS层数据
ads_data = spark.read.json("hdfs://path/to/ads/data")# 关联广告信息维度数据
final_data = ads_data.join(ad_info, "ad_id")# 写入最终数据
final_data.write.mode("overwrite").json("hdfs://path/to/final/data")
数据指标示例
数据指标分为原子指标、复合指标和派生指标。下面以广告点击数据为例说明各类指标的计算。
原子指标:
# 原子指标:广告点击次数
ad_clicks = dwd_data.filter(col("action") == "click").count()
print(f"广告点击次数: {ad_clicks}")
复合指标:
# 复合指标:点击率
total_impressions = dwd_data.filter(col("action") == "impression").count()
click_through_rate = ad_clicks / total_impressions
print(f"点击率: {click_through_rate}")
派生指标:
# 派生指标:按天计算的点击次数
daily_clicks = dwd_data.filter(col("action") == "click").groupBy("date").count()
daily_clicks.show()
结论
通过以上示例代码,我们可以看到数据仓库各个层级的数据处理流程,以及如何定义和计算各种数据指标。这些规范和方法不仅帮助企业构建高效、可维护的数据仓库系统,还能为业务决策提供有力的数据支持。
希望这个简单的示例能够帮助读者更好地理解数据仓库的设计和应用。