js 网站校验手机网站设置在哪里找
今天给大家分享一道链表的好题--链表的深度拷贝,学会这道题,你的链表就可以达到优秀的水平了。力扣
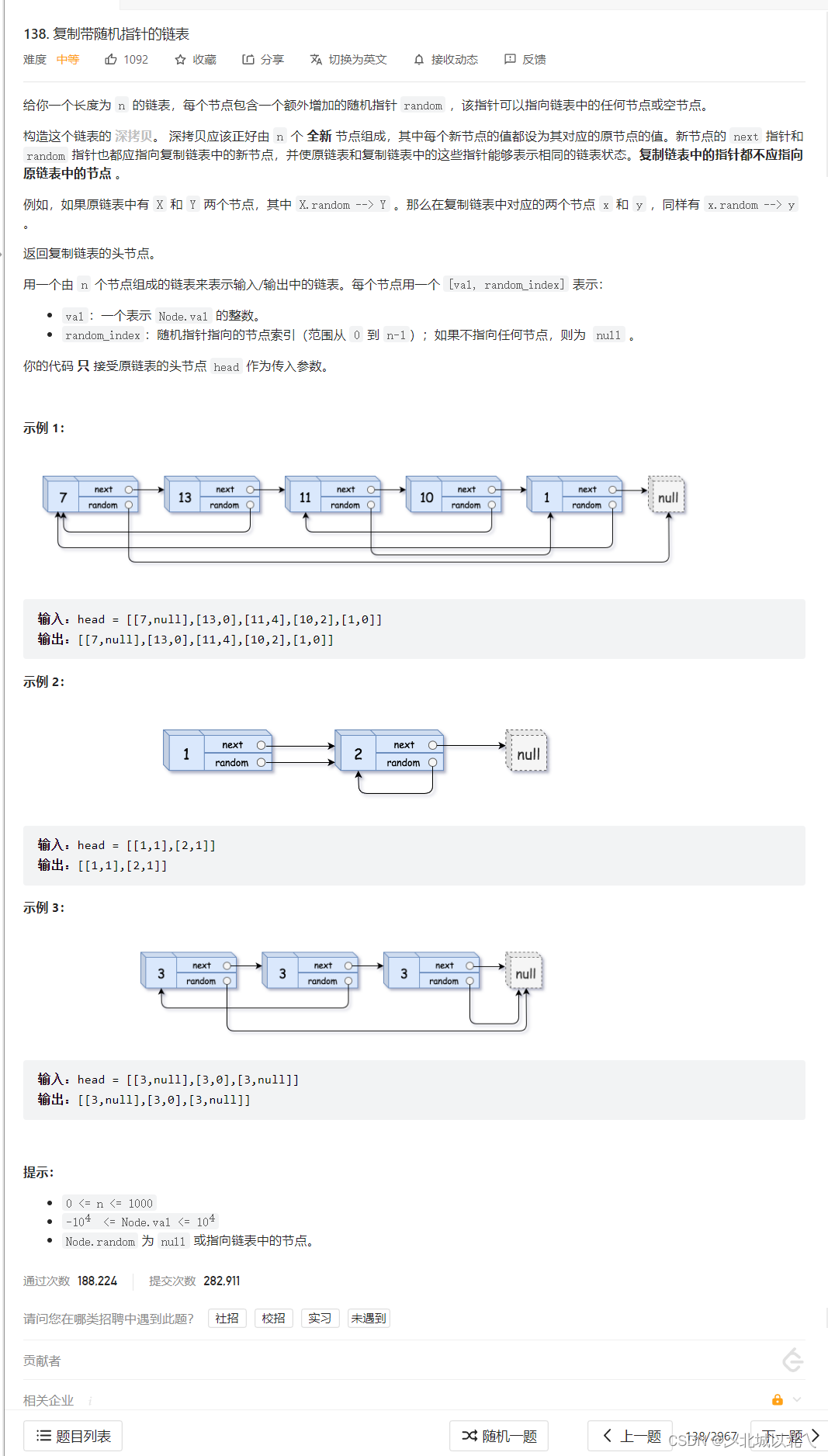
先来理解一下题目意思,即建立一个新的单向链表,里面每个结点的值与对应的原链表相同,并且random指针也要指向新链表中与原链表对应的那个相对位置。(即假设原链表中的第一个结点的random指向原链表的最后一个结点,那么新链表的第一个结点也要指向新链表的最后一个结点,即random指针是链表内部确定相对位置的一个指针)。
首先,拷贝一个新的链表,其对应结点的值与原链表对应结点的值相同是很容易实现的。可以用一个cur指针遍历原链表,然后建立一个新链表头,然后逐个尾插既可。
struct Node* cur=head;struct Node* newhead = NULL;struct Node* tail = NULL;while(cur){//每次尾插都需要一个新结点,其val与原链表对应相等struct Node* newnode = (struct Node*)malloc(sizeof(struct Node));//第一次尾插时if(NULL ==tail){newhead = tail =newnode;newnode->val = cur->val;newnode->next = newnode->random = NULL;}//后续尾插else{tail->next = newnode;tail = tail->next;}//拷贝一个新结点后,cur往后走cur = ucr->next;}此时,只是完成了next链接和val拷贝,random的指向还没有拷贝。
暴力求解O(N^2)
可以建立一个结构体的指针数组 struct Node* arr[n] n为原链表中的结点数
struct Node* arr[n];int count = 0;while(cur){arr[count] = cur->random;count++;cur =cur->next;}
再次利用cur遍历原链表,将每个结点的random保存在创建的结构体指针数组 arr中。
struct Node* newcur=newhead;int newcount=-1;while(newcur){++newcount;//每次进来都拿到原链表的一个randomstruct Node* tmp = arr[newcount];//用tmp保存这个randomcur = head;while(cur != tmp){//遍历原链表,看看此时的random是原链表的第几个结点count++;}//找到新链表中对应的第count个结点struct Node* find = newhead;while(count--){//一共走count步newhead = newhead->next;}//找到了newcur位置的random的指向newcur->random = find;//newcur继续往后走newcur = newcur->next;}
暴力解法虽然也能解决问题,但是时间复杂度为O(N^2),效率低,不推荐。
更优解O(N)
通过暴力解法我们可以发现,寻找random指向的难点在于它是随机的,如果想要确定具体的相对位置(相对于头是第几个)则必须经过2次遍历,那么怎样简化寻找相对位置的过程呢?
想一下random的关系在哪里出现,应该只有原链表中,而我们又想要建立新链表中random的关系,因此我们必须建立原链表与新链表直接的关系,通过原链表的random找到新链表的random。
再借助next指针思考,我们可以将新链表对应的结点连接到原链表上。
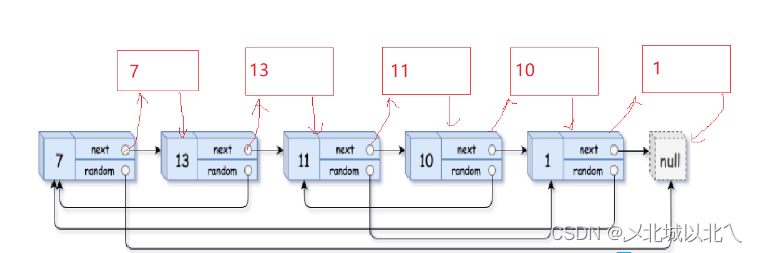
此时逻辑一下子清晰了,每个新结点都在原对应结点的next位置。
例如:对于13这个结点的random连接,新13->random = 原13->random->next,即通过原链表random的查找方式,再加上next,来连接新链表的random。
具体的实现过程分为3个方面。
1、连接原、新链表
struct Node* cur=head;while(cur){//建立新结点并初始化struct Node* newnode = (struct Node*)malloc(sizeof(struct Node));newnode->next = newnode->random =NULL;random->val = cur->val;//先保存一下原结点的下一个结点struct Node* next = cur->next;//将新结点连接到原链表cur->next = newnode;newnode->next = next;//cur继续往后走cur = next;}2、建立新链表的random联系
cur = head;while(cur){//确保cur不为NULL,再建立copy指向cur的nextstruct Node* copy = cur->next;//建立copy的random联系时,要确保其不为空,否则不能进行next操作//因此这里讨论一下原链表的random是否为空if(NULL == cur->random){copy->random = NULL;}else{ copy-> random = cur->random->next;}//连接后cur继续往后走cur = copy->next;}要注意,copy指针和cur指针移动的位置,可以理解为cur不为空时,建立copy指向此时cur的下一个,完成相关连接后copy丢弃,cur往后走,copy只起到临时变量的作用(连接后便丢弃)。
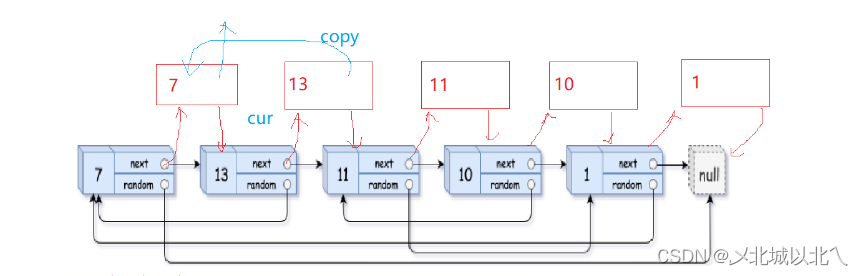
3、分离原、新链表
分离的过程直接将copy部分的结点尾插到一个新结点即可
struct Node* newhead=NULL,*tail=NULL;cur=head;while(cur){struct Node* copy = cur->next;struct Node* next = copy->next;if(NULL == tail)//第一次尾插{newhead = tail =copy;}else//后续尾插{tail->next = copy;//tail往后走,指向新的最后一个结点tail = tail->next;}//分离原链表,cur继续往后走cur->next=next;cur= next;}return newhead;这部分要注意,else内部tail往下走是后续尾插才有的操作。
总结:为了优化代码,使时间复杂度变为O(N),必须建立原来链表的新链表直接的联系,借助原链表的random->next,来连接新链表的random。
所以说,没有关系的话,那就去勇敢的建立关系吧。
