用flash做的网站欣赏制作网页首页教程
前言
Apache Flink,作为大数据处理领域的璀璨明星,以其独特的流处理和批处理一体化模型,成为众多企业和开发者的首选。它不仅能够在处理无界数据流时展现出卓越的实时性能,还能在有界数据批处理上达到高效稳定的效果。本文将简要介绍Flink的基本概念,以及如何在Yarn上安装和配置Flink。
初识Flink的魅力
Apache Flink是一个开源的计算框架,专为分布式数据流和批量数据处理而设计。它支持对有界和无界数据流进行状态化的计算,使得数据处理不再局限于传统的批处理或单一的流处理模式。这种一体化模型让Flink在实时分析和离线计算之间架起了桥梁,满足了多样化的数据处理需求。
Flink的核心优势在于其高效的内存执行速度和出色的容错机制。它采用Java和Scala编写,提供了丰富的API和灵活的窗口操作,使得开发者能够轻松构建复杂的数据处理流程。此外,Flink还保证了严格的一次性语义,确保每条数据只被处理一次,从而避免了数据重复或丢失的问题。
在实时处理方面,Flink展现了无与伦比的优势。它的延迟可以低至毫秒级别,远优于传统的批处理框架。这使得Flink在处理需要高实时性的应用场景时,如金融交易分析、在线广告推荐等,具有显著的优势。
Flink与Yarn的完美结合
Yarn(Yet Another Resource Negotiator)是Apache Hadoop的一个资源管理器,负责在集群中分配和管理资源。将Flink与Yarn结合使用,可以充分发挥Yarn的资源调度优势,提升Flink任务的执行效率。
在Yarn上运行Flink主要有两种模式:会话模式(Session Mode)和每作业模式(Per-Job Mode)。
会话模式允许用户预先启动一个Flink集群,并为其分配固定的资源。一旦集群启动,用户就可以将多个作业提交到该集群上执行。这种模式适用于需要长时间运行多个作业的场景,但缺点是即使在没有作业运行时,集群也会占用一定的资源。
每作业模式则更为灵活。在这种模式下,每次提交作业时,Flink都会为其创建一个独立的集群,并根据作业的需求动态分配资源。作业执行完毕后,集群会自动销毁,释放资源。这种模式适用于作业量较大且作业间相互独立的场景,能够充分利用集群资源并减少资源浪费。
安装与配置Flink on Yarn
要在Yarn上安装和配置Flink,首先需要下载并解压Flink的发行版。然后,根据集群的实际情况修改Flink的配置文件(如flink-conf.yaml),设置相关的参数,如Yarn集群的地址、任务的并行度等。接下来,将Flink的相关文件(如jar包和配置文件)上传到集群的指定位置,并配置环境变量以便在集群中运行Flink命令。
完成上述步骤后,就可以通过Flink提供的命令行工具或API提交作业到Yarn集群上执行了。Flink会根据作业的需求和Yarn集群的资源状况,动态地创建和管理集群,确保作业的顺利执行。
总结
Apache Flink以其独特的流处理和批处理一体化模型,以及高效的内存执行速度和出色的容错机制,成为大数据处理领域的佼佼者。与Yarn的结合使用,更是让Flink在集群环境中发挥了最大的性能优势。通过合理的安装和配置,Flink on Yarn将为大数据处理带来前所未有的速度和稳定性,助力企业在实时分析和离线计算方面取得更大的成功。
安装部署
解压缩文件
tar -zxvf flink-1.14.0-bin-scala_2.12.tgz -C /opt/module/
添加环境变量
#FLINK_HOME
export FLINK_HOME=/opt/module/flink-1.14.0
export PATH=$PATH:$FLINK_HOME/bin
export HADOOP_CLASSPATH=`hadoop classpath`
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
刷新环境变量,使其生效
source /etc/profile
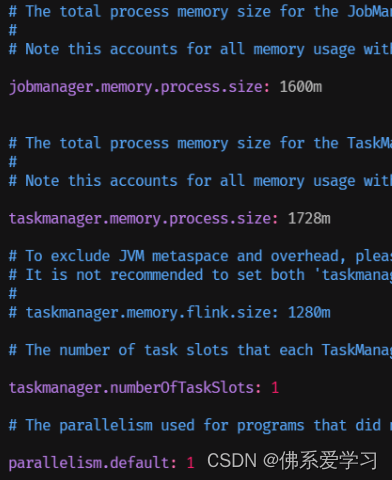
进入 conf 目录,修改 flink-conf.yaml 文件(可以使用默认值)
jobmanager.memory.process.size: 1600m
taskmanager.memory.process.size: 1728m
taskmanager.numberOfTaskSlots: 1
parallelism.default: 1
在bigdata_env.sh文件中添加export HADOOP_CLASSPATH=`hadoop classpath`
在flink的conf目录下,修改 flink-conf.yaml 文件添加的内容如下classloader.check leaked classloader: false
以per job 运行文件
flink run -m yarn-cluster -p 2 -yjm 2G -ytm 2G $FLINK_HOME/examples/batch/WordCount.jar