南浔区建设局 网站做前端常用的网站及软件

今天给大家带来的是滑动窗口的类型题,都是十分经典的。
1,无重复字符的最长子串
看例三,我们顺便来说一下子串和子序列的含义
子串是从字符串里面抽出来的一部分,不可以有间隔,顺序也不能打乱。
子序列也是从字符串里面抽出来一部分,可以有间隔,顺序也不能打乱。
如图

可以看出来,如果是子序列问题,一般会比子串要更难一点。
不扯了,接下来进行这道题题目的讲解
第一种思路,也就是最简单的思路
那就是暴力求解。因为这道题本来就是只含有数字,字母符号,空格等组成。查看ASCII表,可以发现范围在128以内。当然我们也可以创建一个哈希表用来记录。然后分别从字符串的每个位置向后寻找,保留一个最大值即可。
class Solution {
public:
int lengthOfLongestSubstring(string s) {int ret = 0; // 记录结果int n = s.length();// 1. 枚举从不同位置开始的最⻓重复⼦串// 枚举起始位置for (int i = 0; i < n; i++){// 创建⼀个哈希表,统计频次int hash[128] = { 0 };// 寻找结束为⽌for (int j = i; j < n; j++){hash[s[j]]++; // 统计字符出现的频次if (hash[s[j]] > 1) // 如果出现重复的break;// 如果没有重复,就更新 retret = max(ret, j - i + 1);}}// 2. 返回结果return ret;
}
};
运行后如图
还有一种方式就是滑动窗口,滑动窗口的思想就是两个同方向移动的指针,然后判断指针范围内我们所要寻找的,或者要统计的。
使用两个指针,left和right。
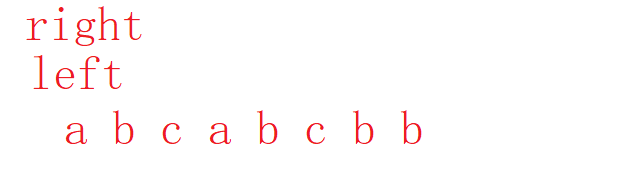
如果right和left中的元素没有重复值,那right就继续右移,设置一个max变量保存最长数,在窗口向后滑动时不断更新最大值。如果有重复的元素,就让left右移,直到窗口中没有重复元素为止,这样只需要遍历一遍就可以知道最长字符串的长度。
代码如下
class Solution {
public:
int lengthOfLongestSubstring(string s) {int hash[129] = { 0 };int left = 0, right = 0;int max = 0;while (right < s.size()){hash[s[right]]++; while (hash[s[right]] != 1)//如果某个元素的数量大于2{hash[s[left]]--;//就右移left,直到该元素数量恢复为1left++;}if (right - left + 1 > max)//更新最大值{max = right - left + 1;}right++;}cout << max;return max;
}
};
暴力解法的时间复杂度明显为O(N2),而滑动窗口的时间复杂度为O(N)。
第二道题
最大连续1的个数

这道题很有意思的地方就是可以翻转,将0翻转为1。
这道题还是可以暴力解法,和第一道题很是类似,就是多了可以翻转这一步。但是我们可以这样想,一直遍历1,如果是0就翻转,上道题我们判断的是是否有重复的字符,这道题呢?我们不用想的那么复杂,还是设置两个变量left和right,同样遇到1就继续++right,如果遇到0,就判断窗口内0的个数,如果个数大于K就向右移动left,直到窗口内0的个数小于k即可,这样就只需要遍历一遍数组即可得出答案。
用动态图来演示一下

class Solution {
public:int longestOnes(vector<int>& nums, int k) {int left=0,right=0;int ret=0;while(right<nums.size())//确定范围{if(nums[right]==0){k--;if(k<0)//k表示还可以翻转的0的个数{while(k!=0){if(nums[left]==0){k++;//如果left跳过了一个0,就++可翻转数left++;}else{left++;}}}}right++;ret=max(right-left,ret);//记录最大值}return ret;}
};
运行后如图
第三题
水果成篮
 题目很长,但是其实很容易理解,最主要的一点就是不能超过两种数,其实就是最长不重复子串的改版,这道题找的是最长只存在两种元素的最长子串的长度。
题目很长,但是其实很容易理解,最主要的一点就是不能超过两种数,其实就是最长不重复子串的改版,这道题找的是最长只存在两种元素的最长子串的长度。
至于思路还有做题方法可以说和上边两道题很像。
用一个例子说明一下,这道题的暴力解法还是不停遍历,从数组的每一个位置开始,然后保留最大值。

代码如下
class Solution {
public:int totalFruit(vector<int>& fruits) {int hash[100001] = { 0 };int left = 0, right = 0;int kind = 0;int ret = 0;while (right < fruits.size()){if (hash[fruits[right]] == 0){kind++;}hash[fruits[right]]++;while(kind>2){hash[fruits[left]]--;if(hash[fruits[left]]==0){kind--;}left++;}ret = max(right-left+1, ret);right++;}return ret;
}
};
这里我们知道数据的范围,所以直接用一个数组代替哈希表。前三题的思路都十分相似。
第四题
找到字符串中所有的字母异位词

看一看例子,就知道异位词的含义了。

这道题的思路也很明显,和前边的题目又有一点不一样,我们首先要记录p字符串中的字母,然后从s字符串中利用滑动窗口查找,如果滑动窗口中的字符符合p字符串中所有字符个数。如果不符合,那就移动right和left。当然,p字符串的长度是一定的,所以滑动窗口的长度也是一定的。
我们可以用两个数组模拟哈希表,一个统计p字符串中的每个字母的个数,另一个是统计每一个字符出现的个数。
在滑动的时候,如果符合就++count,然后设置一个vector数组,将符合的位置(就是left的位置)放进数组中。然后将该数组返回。
class Solution
{
public:
vector<int> findAnagrams(string s, string p)
{vector<int> ret;int hash1[26] = { 0 }; // 统计字符串 p 中每个字符出现的个数for(auto ch : p) hash1[ch - 'a']++;int hash2[26] = { 0 }; // 统计窗⼝⾥⾯的每⼀个字符出现的个数int m = p.size();for(int left = 0, right = 0, count = 0; right < s.size(); right++){char in = s[right];// 进窗⼝ + 维护 countif(++hash2[in - 'a'] <= hash1[in - 'a']) count++;if(right - left + 1 > m) // 判断{char out = s[left++];// 出窗⼝ + 维护 countif(hash2[out - 'a']-- <= hash1[out - 'a']) count--;}// 更新结果if(count == m) ret.push_back(left);}return ret;
}
};
运行后如图