新手怎么做网站内容维护重庆网站建设拓云
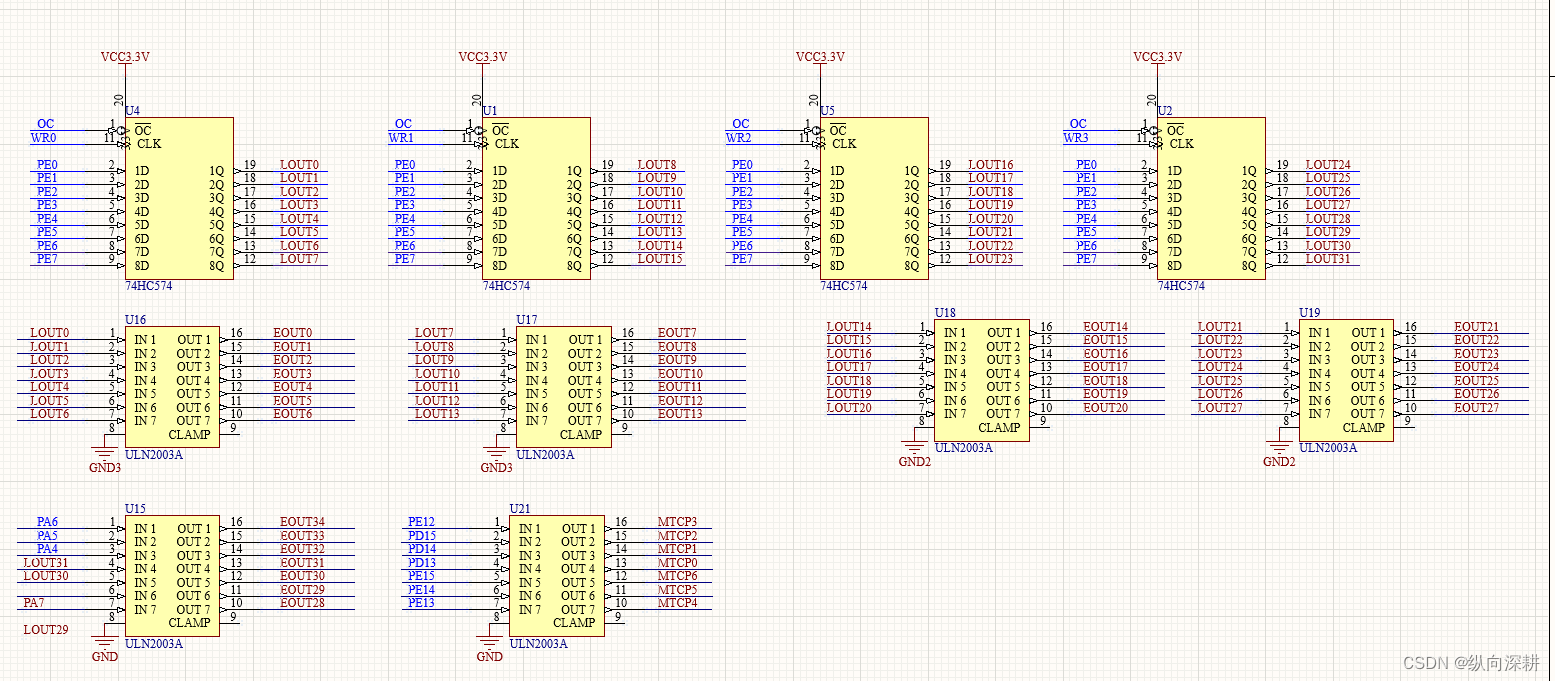
一、货道选通矩阵电路,类似扫描电路,驱动哪个电机,就打开相应的行线与列线输出
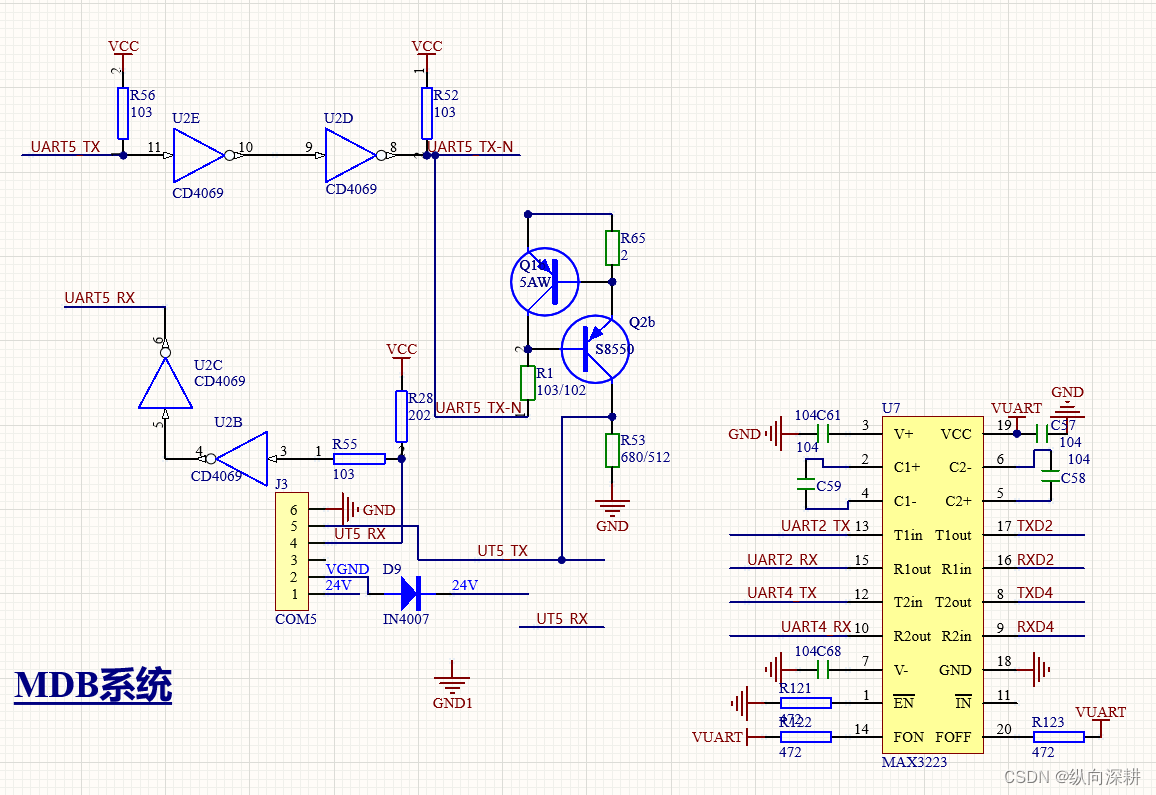
二、MDB纸币器,虽然现在国内都是手机支付,但如果机器还是外销国外还是有用
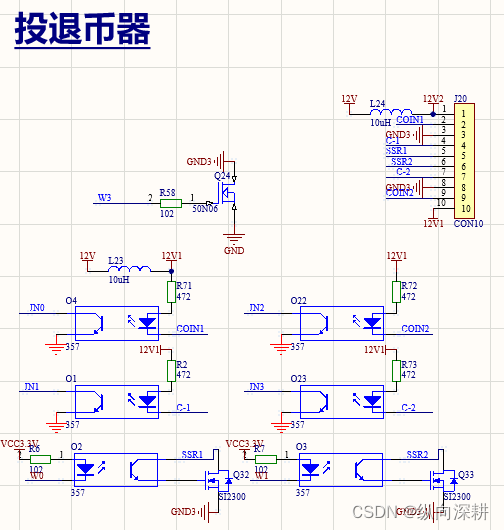
三、硬币器电路,投币与退币,脉冲信号
其它都是普通的数字电路
一、货道选通矩阵电路,类似扫描电路,驱动哪个电机,就打开相应的行线与列线输出
二、MDB纸币器,虽然现在国内都是手机支付,但如果机器还是外销国外还是有用
三、硬币器电路,投币与退币,脉冲信号
其它都是普通的数字电路