简单模板网站制作时间wordpress一个页面如何连接到首页
LCD(Liquid Crystal Display)液晶屏,作为电子产品的重要组成部分,是终端用户与电子产品交互的重要载体。现在市场上的LCD,按照尺寸、功能、接口、用途等分为很多种,本文主要介绍如下两种LCD物理接口:
1) MCU接口(8080接口)
2) SPI接口
当然还有其他接口,比如LVDS接口、DSI接口、EDP接口、RGB接口、MIPI接口等,其中很多接口并不常用,有些安排下篇文章分享,所以在这里就不在详述。
一、 MCU接口
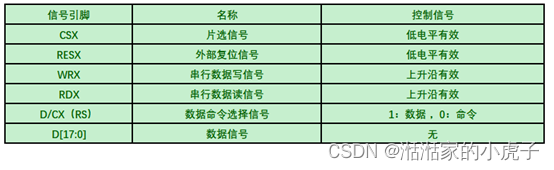
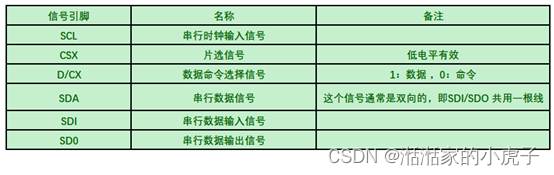
目前最常用的连接模式,主要用于单片机领域里,因此得名MCU接口,现在很多中低端的手机,或手表有在使用,价格较为便宜。MCU接口其本质是由英特尔(Intel)提出的8080总线标准。8080是一种并行接口,所以MCU接口也被称为8080接口,也有人称其为DBI(Data Bus Interface)数据总线接口。数据位传输有8位、9位、16位、18位。连线信号详细见下表:
优点是:控制简单方便,无需时钟和同步信号。缺点是:要耗费GRAM,所以难以做大尺寸屏。
1、 不同并口传输接口
下图是不同bit位与8080接口与单片机系统接口的示例

2、 写信号周期
WRX信号从高电平拉低,然后在写周期中被拉高。主机在写周期内发送数据信息,当LCD在WRX的上升沿上从主机读取数据信息。当D/CX信号拉低时,接口上的输入数据被认为是command地址信息。当D/CX信号拉高时,接口上的数据是SRAM数据或command 参数信息。所有信号传输,需要将CSX拉低后,才可以进行。
下图显示了8080 MCU接口的写周期。
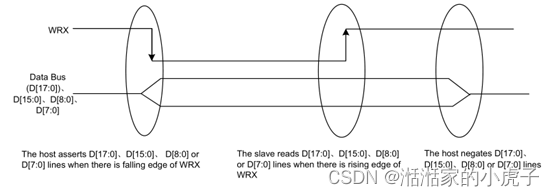
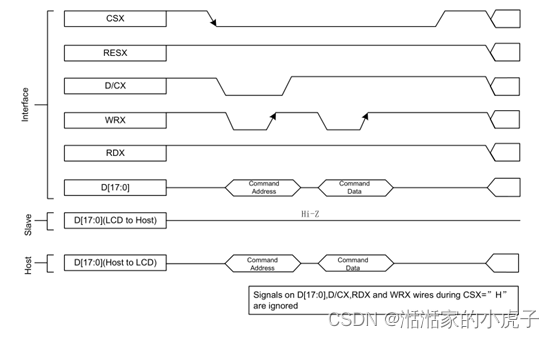
3、 读信号周期
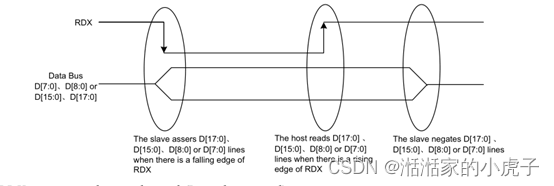
RDX信号从高电平拉低,然后在读周期中被拉高。主机在读周期内发送数据信息,当LCD在RDX的上升沿上从主机读取数据信息。当D/CX信号拉低时,接口上的输入数据被认为是command地址信息。当D/CX信号拉高时,接口上的数据是SRAM数据或command 参数信息。所有信号传输,需要将CSX拉低后,才可以进行。
下图显示了8080 MCU接口的读周期。
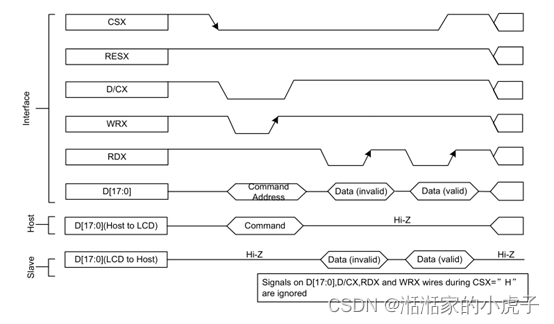
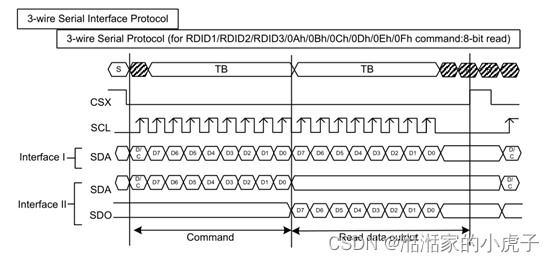
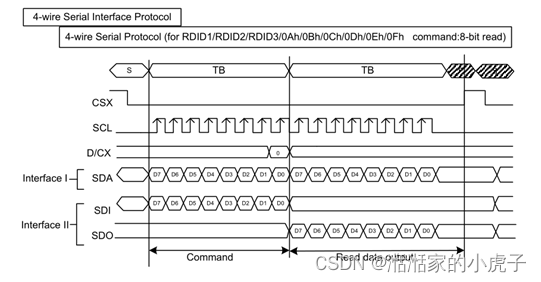
二、 SPI接口
目前比较常规的使用方式,因为传输线少,比较受欢迎。但是因为传输线少,所以传输带宽有限,多应于小尺寸液晶屏。当前接口可以分为如下几种类型:
Serial interface I:
1)3线9比特模式1(3-wire 9-bit data serial interface I)
2)4线8比特模式1(4-wire 8-bit data serial interface I)
Serial interface II:
1)3线9比特模式2(3-wire 9-bit data serial interface II)
2)4线8比特模式2(4-wire 8-bit data serial interface II)
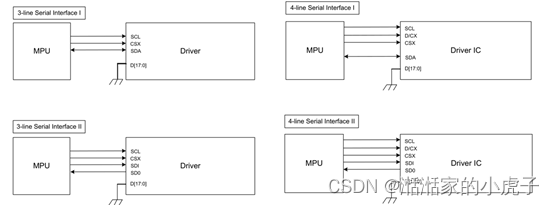
1、不同串口传输接口
下图是不同类型SPI接口与单片机系统接口的示例
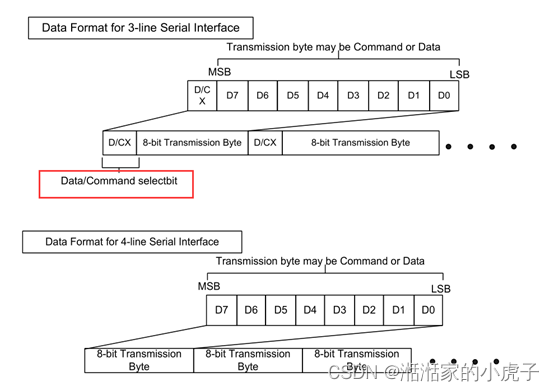
2、写信号周期
接口的写模式是指主机向LCD写入命令或数据。3线串行数据包包含一个数据/命令选择位(D/CX)和一个传输字节。如果D/CX位为“低”,则传输字节是command的地址。如果D/CX位“高”, 接口上的数据是SRAM数据或command 参数信息。任何指令都可以以任何顺序按照先发送MSB的方式发送给LCD。CSX处于高状态时,输出传输是没有意义的。CSX是电平是开始数据传输。
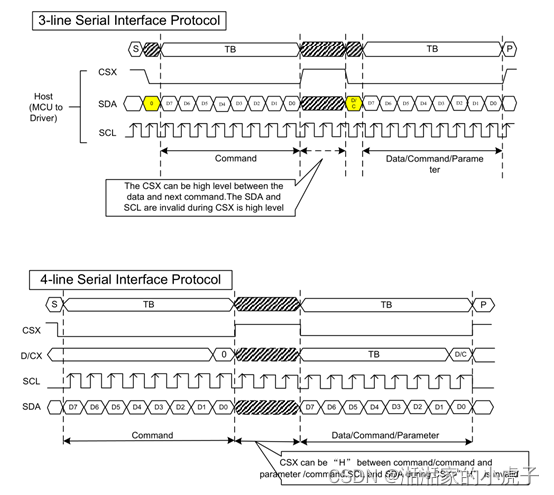
3、读信号周期
接口的读模式是指主机LCD中读取寄存器的参数。主机必须发送一个命令(读取ID或寄存器命令),然后进行传输数据。采样标准按照SPI协议标准进行采样。